





Babble Buddy
Problem & Objective
Our capstone project, Babble Buddy, is an online speech therapy tool aims to address the shortage of Speech-Language Pathologists (SLPs) by providing targeted support to children in need of speech therapy. Introducing a digital tool for online speech therapy, the project seeks to overcome the limitations of traditional therapy methods, ensuring accessibility and effectiveness in reaching children struggling with pronunciation. By leveraging technology and expertise, the team aims to empower every child to overcome speech challenges with confidence, ultimately striving for a future where every voice is heard and valued.
Check out our project here
Mission
Help every child speak with confidence
Data Source & Technical Approach
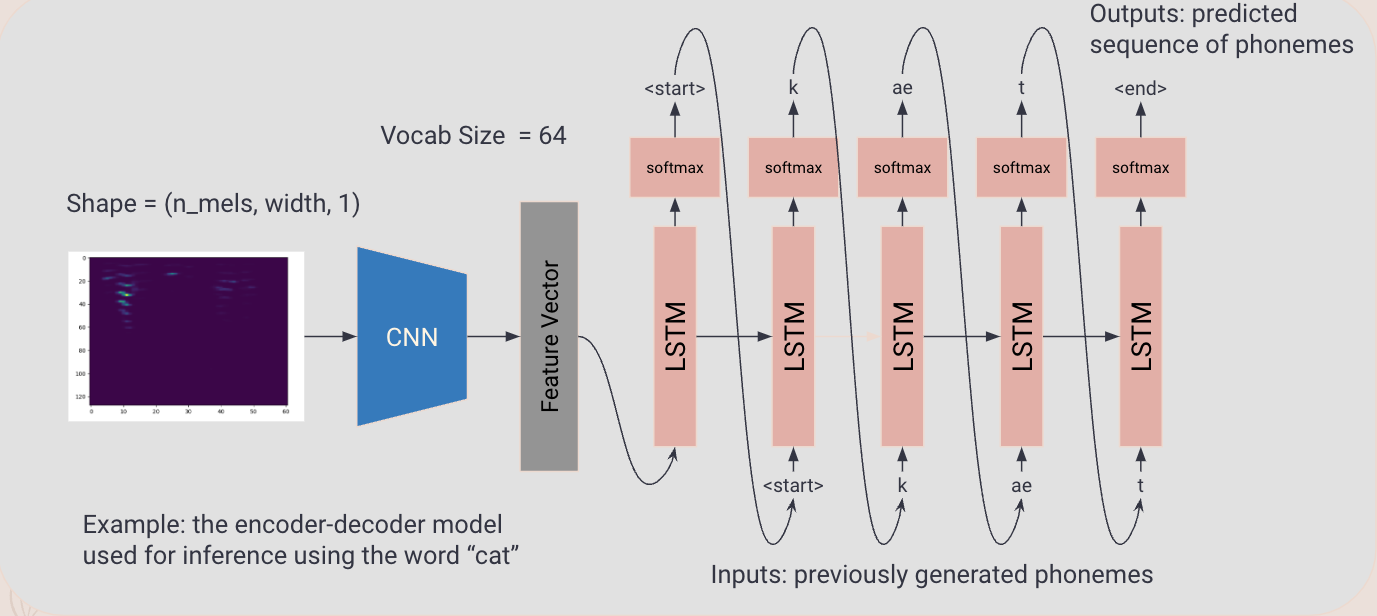
Custom Model:
- Dataset:
- Original dataset: DARPA-TIMIT Acoustic-Phonetic Continuous Speech Corpus. Include sound files paired with phonetic transcriptions with timestamps. The dataset includes adult american english speakers grouped by accent from 8 regional
- Custom dataset: created by slicing the audio into discrete phonemes, applying data augmentations such as pitch shift and noise addition, and randomly recombining them.
- Custom model would be made specifically for the task of phoneme recognition and allow flexibility.
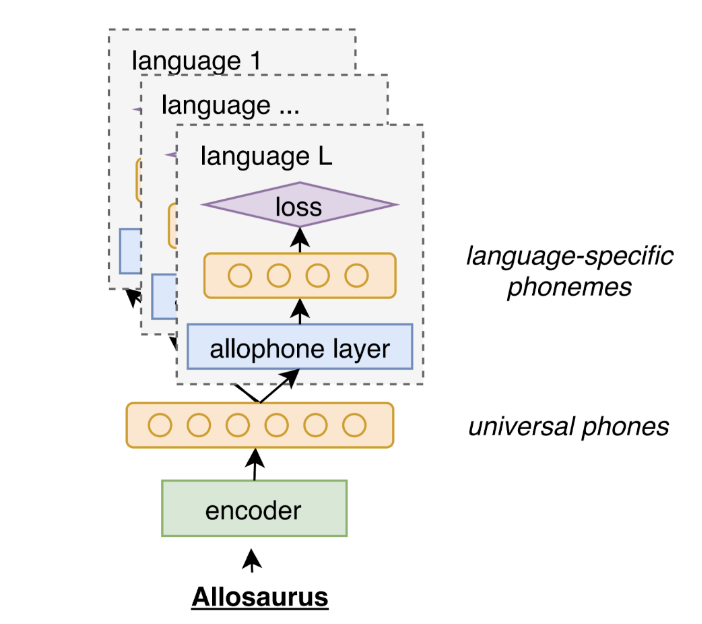
Pretrained Model: Allosaurus
-
Allosaurus is a pre-trained universal phone recognizer. It is trained on over 2 million utterances from 14 different languages. Its creators trained it with the objective of having a multilingual phone recognizer, which makes it quite suitable for our task despite having been created for a very different purpose.
-
The architecture of allosaurus is similar to that of a traditional automatic speech recognition system, but it has some innovations that make it suitable for universal phone recognition as opposed to being language-specific. Similar to our CNN-LSTM model, Allosaurus also relies on an LSTM-based classifier to predict phonemes from the extracted features, but its performance is much better.
Model Evaluation
- Baseline dictionary model: Given a prompt sentence, assume that the correct phonetic transcription of the response will be the dictionary correct response
- BLEU: 0.456
- Pre-trained Allosaurus Model:
- BLEU: 0.473, impacted by not exact one to one mapping of phonemes between IPA phonetic symbol to Alphabetic phonemes.
User Feedback
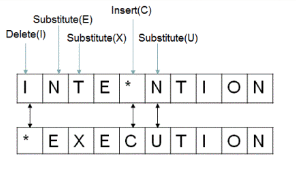
- Minimum Edit Distance algorithm assigns error to particular sounds
- Flattening of sounds into larger categories
- Sounds correspond to words
- SLP defined error categories are individually labeled and returned
Course
Data Science 210. Capstone , Spring 2024More Information
