

 Saxenian")
")




SignSense: American Sign Language Translation
Problem & Motivation
Hearing loss in children is a critical and often overlooked issue. It represents the most common birth defect in the United States, affecting approximately 12,000 infants annually, which translates to around 3 in every 1,000 babies. Furthermore, over 90% of children with permanent hearing loss have two hearing parents, making it less likely for both children and parents to learn sign language. American Sign Language (ASL) poses a significant challenge for English speakers. Learning it demands considerable time and resources that many parents may not possess.
Children with hearing loss commonly encounter challenges across multiple aspects of their development, including speech and language skills, social interactions, classroom engagement, and mental well-being. The impediment to their hearing can hinder the acquisition of language skills, hinder communication with peers, limit comprehension of classroom instructions, and restrict participation in group activities. These difficulties may result in feelings of isolation, frustration, and diminished self-esteem, ultimately impacting their mental health and overall quality of life. It is imperative to implement strategies and initiatives that enhance the ability to comprehend ASL for individuals of all age groups.
Currently, the state of the art in automated ASL translation falls considerably short of solving the problem. In this project we take a novel approach to the machine translation of ASL, aiming to develop a TensorFlow model capable of interpreting ASL signs from video data. Utilizing computer vision and natural language processing techniques in combination with diverse video datasets, our proposed model attempts to perform machine translation for sentence-level ASLs.
Data
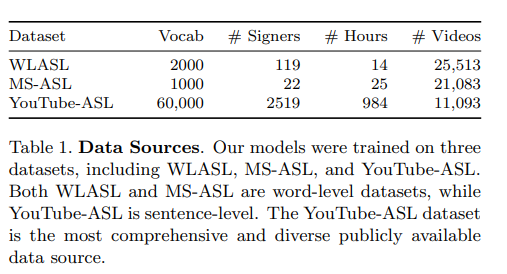
We made use of three different data sources, detailed in Table 1 - the Microsoft ASL Dataset (MS-ASL) and Word-Level ASL Dataset (WLASL) contain videos of individual words, while the YouTube-ASL dataset contains full sentences or sequences of words. For our experiment, we worked with videos from the YouTube-ASL dataset, downloaded along with their respective English captions. We downloaded the full WLASL dataset and a subset of the MS-ASL dataset containing only the words already present in the WLASL dataset. The processing consisted of passing the videos through OpenCV and converting the frames into RGB numpy arrays. Each video was then divided into clips corresponding to each caption. The video frames for each caption were then cropped to the center square and resized to 224 x 224, such that the final dimensions for a video of length N would be N × 224 × 224 × 3, where 3 is the number of channels (in RGB).
The captions corresponding to the YouTube-ASL dataset were also cleaned by converting them to lowercase and removing special characters (keeping punctuation) and empty spacing. We also removed any captions that consisted of only bracketed words (e.g., [music], or [demonstrates sign]). While nearly all captions in the dataset occurred uniquely, there were a few phrases that occurred up to 30 times. To avoid biasing the model on these phrases and terms, we sampled up to 5 occurrences for each caption.
Modeling Approach
Our model architecture consisted of a two-step approach. First, we used a convolutional network model to extract video features in the form of embeddings from our data. Next, we passed the output video embeddings into a large language model for translation.
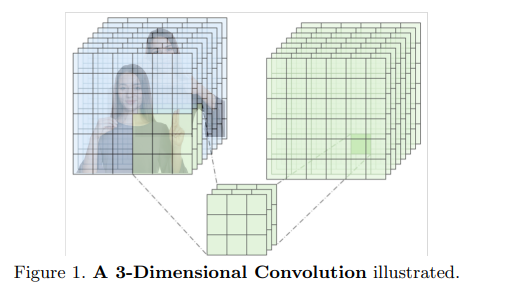
To generate the video embeddings, we used MoViNets, an action-recognition classification model that makes use of 3D convolutions, illustrated in Figure 1, to extract not only image features from each video frame, but also temporal features across the video frames. The MoViNets model has been pre-trained on the Kinetics600 dataset, and outperforms many of the state of the art models while also being lighter weight with only 3 million parameters.
For the large language model, we used T5, an encoder-decoder model that has been pre-trained on translation tasks and is relatively lightweight compared to other large language models with 222 million parameters.
Action Recognition Classifier
We used the MoViNets A2-base model architecture, shown in Table 2, which consists of six 3D convolutional blocks.

Because the video embeddings needed to match the shape of the input embeddings for the T5 model, we had to modify MoViNets’s architecture. To do this, we removed the final four layers from the model and replaced them with two 2D convolutions followed by a flattening layer to reduce the dimensionality down to 768. We then designed the model to have two outputs for both the classification and the video embedding. The output video embedding preserves the number of frames, N, in the video such that the final shape is N×768. The modified MoViNets architecture is shown in Table 3.

With the modified architecture defined, we finetuned the MoViNets model as a classifier on the ASL word-level datasets, including both WLASL and MSASL. Due to sparse coverage of words and considerably slow training times, we reduced the dataset to only words with at least 27 occurrences, resulting in the 107 most frequent words. Since the model was heavily swayed by imbalanced classes, we dropped data such that no class had more than 50 occurrences, resulting in a total of 2,518 data points in the training set. To further augment the dataset, we re-sampled 2 videos from each class in the training dataset and applied horizontal flip, increasing our training dataset to 2732 samples. This not only helped to increase the number of samples per class, but also helped to address right vs. left-handed ASL signers.
We used the RMSprop optimizer, CategoricalCrossentropy loss function, and a CosineDecay learning rate scheduler for fine-tuning. Both the optimizer and loss function were only applied to the classifier output; the video embedding output was not trained. Due to memory limitations, we had to unfreeze one 3D convolution block at a time, train for 2 epochs, and then progress to the next block. We trained the model for 48 hours over 9 epochs on an NVIDIA A10G Tensor Core GPU. Although the model continued to show improvement over each epoch, we decided to prematurely end the training due to resource constraints.
Language Model
For the language modeling component, we used the T5-base model from Hugging Face. We additionally tested the T5-large, T5 v1.1-base/large, and FLAN-base/large models, but found the original T5 models to work best. We opted to use the base model due to GPU memory constraints. The T5-base model has an embedding size of 768.
For training, since we did not have tokenized text for the input to the model, we had to bypass the embedding layer and instead input our video embeddings (with dimensions N× 768, and padded to a fixed sequence length) directly into the encoder. We passed the tokenized caption corresponding to the video as the label, setting the maximum token length to 128 and padding or truncating the captions as needed.
We found that the model struggled to learn when trained on the captions. The captions did not always form complete sentences, sometimes beginning in the middle of a sentence or consisting of only one or two words. This lack of context or grammatical structure in the captions presented an additional challenge to the model. For this reason, we fine-tuned T5 in a two step approach, first training the model to generate individual words, and then further fine-tuning it to generate full captions.
Word-Level Generation
Before training on complete sentences, we started by training T5 to generate predictions for single words at a time. We passed a dataset of 25K video embeddings of words from the WLASL and MS-ASL datasets, containing 2000 unique words, and allowed the model to generate up to 128 tokens. For the text generation parameters, we set the temperature to 0.01, top k to 50, and top p to 0.90.
For fine-tuning, we used Adafactor for the optimizer, SparseCategoricalCrossentropy for the loss, and a CosineDecay learning rate scheduler. We limited the input sequence length to 265 frames, padding or truncating all video embeddings to this length and providing its corresponding attention mask. We set the batch size to 32 (the largest our GPU memory could handle), used an initial learning rate of 0.0001 with a warm-up of 50 steps, and trained the model for 15 epochs.
Sentence-Level Generation
After fine-tuning the T5 model on individual words, we did further fine-tuning to generate full captions or sentences. Due to resource constraints, we were limited to a dataset of 20K captions from YouTube-ASL, containing roughly 13K unique words.
We used a similar training configuration as used for the word-level fine-tuning but set the initial learning rate to 0.0005 with a warm-up of 600 steps. The maximum input sequence length was set to 320 frames (the 95th percentile for frame counts across our captions). All videos were either padded or cropped to this length and input to the model along with an attention mask. Because of the larger input data size, our batch size was reduced to 24. We trained the model for 10 epochs.
Evaluation
Modified MoViNets Classifier
As a classifier, our modified MoViNets model achieved a final top1 validation accuracy of 0.17, and a top-5 validation accuracy of 0.29. Although these are low scores, we did not need a strong classifier since our interest was purely in the intermediate embeddings.
With the model trained, we iterated through all our data in WLASL, MS-ASL, and YouTube-ASL and generated our MoViNets video embeddings, preserving the original number of frames.
T5 Word-Level Generator
Our T5 model, fine-tuned on individual words, achieved a top-1 validation accuracy score of 0.56, an improvement of 0.39 compared to the 0.17 accuracy from the MoViNets classifier. It is worth noting that the MoViNets classifier was trained on only 107 words, while T5 was now able to classify 2000 unique words correctly more than 50% the time.
Looking deeper into the model predictions, we found that the model would often predict synonyms or related terms instead. Common themes like animals, numbers or locations would often get confused. Upon manual inspection of a few examples like this we found that in some cases the same video file would be listed twice in the dataset under two translations (eg. picture and image, cop and police, or eyeglasses and glasses). In other cases, we found that related terms would have similar root hand gestures. For example, the signs for some colors follow a similar pattern, involving a twisting wrist motion of the hand near the chin, but with different shapes of the fingers or hand. There are further instances, such as the signs for care and for careful, which have identical arm and hand gestures but differ only in facial expression. The model likely mislabeled cases like these due to limitations in the MoViNets model. With a significantly larger dataset, both in size and in number of classes, the CNN model could learn to identify these features. Alternatively, the model may require multiple input embeddings, potentially including multiple CNN models each trained to focus on one subpart of a gesture (eg. hands, facial expression, body pose).
In order to more fairly evaluate the model performance given the similarly themed terms that were mislabeled, we used the SentenceTransformers all-mpnetbase-v2 model to compute the cosine similarity between predictions and labels. We found an average cosine similarity of 0.65.
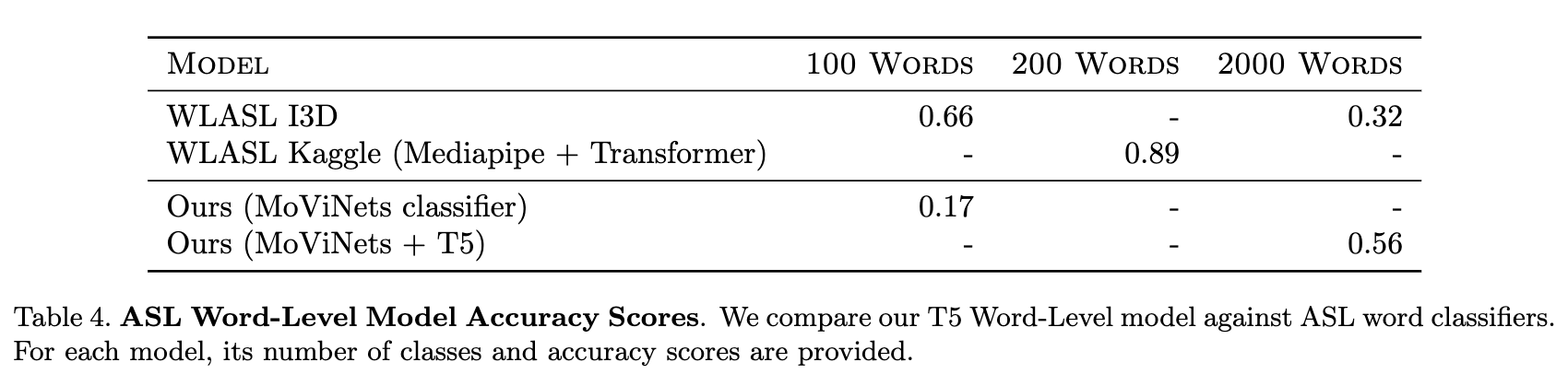
Although this model is a text generator rather than a classifier, we compare our accuracy against other state-of-the-art ASL word classifiers as shown in Table 4 above. To date, there are highly accurate word-level models that make use of transformer architectures, but these models are mostly limited to small numbers of classes and tend to degrade in performance as the number of classes increases. Although the T5 word-level accuracy is only 0.56, it is an improvement over the WLASL I3D model.
T5 Sentence-Level Generator
The fine-tuned sentence-level model achieved a validation BLEU score of 1.98 (calculated using SacreBLEU version 2) and an average SentenceTransformers cosine similarity of 0.21.
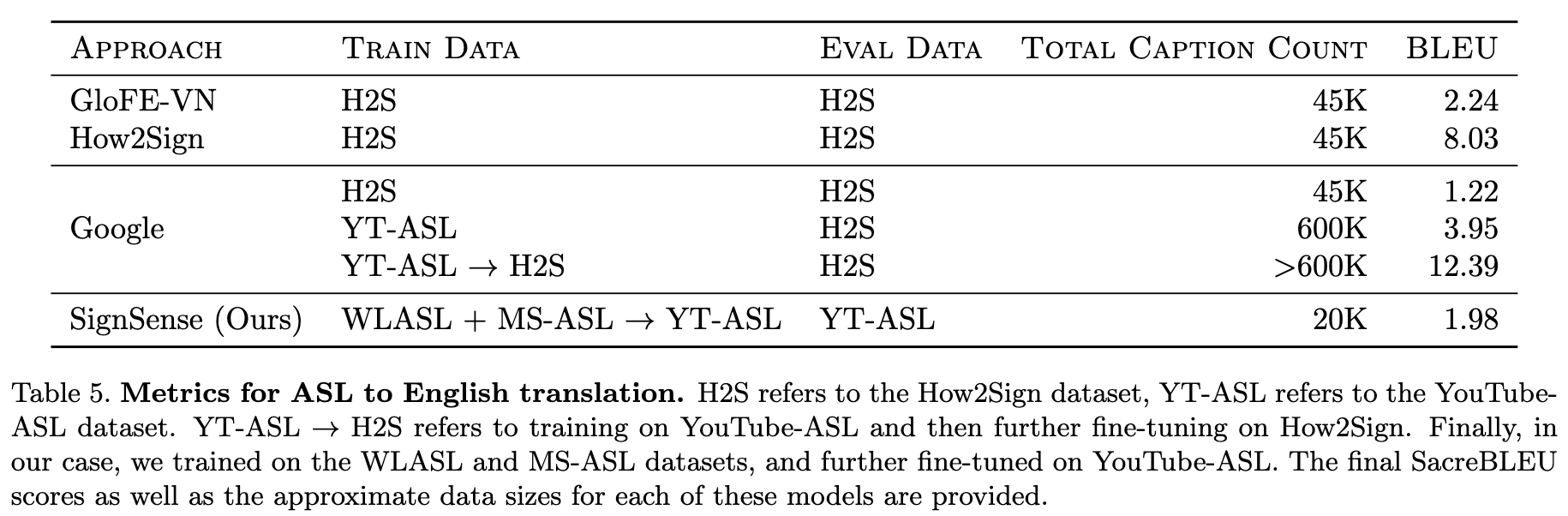
Table 5 compares our model’s performance against the top-performing models for ASL translation from Google and How2Sign. It is important to note that in both their cases, they tested their models on a dataset of how-to videos, which have more focused language than the general videos we used in our evaluation, so these metrics are not exactly one-to-one.
We would also like to highlight that while our model falls short of the best-achieved metrics, it has been trained on significantly fewer data points, and evaluated on a broader test dataset of general YouTubeASL videos. The top performing model, created by the Google team, achieved a top BLEU score of 12.39 when trained on over 600K captions; but when trained on a dataset of 45K captions, its BLEU score was 1.22 when evaluated on the How2Sign dataset. In comparison, our model achieved a BLEU score of 1.98 when evaluated on YouTube-ASL data despite being trained on only 20K captions.

To better understand how the dataset size impacted our model, we performed an experiment where we trained for just 5 epochs on increasingly larger training sets. Figure 2 demonstrates that the model improves considerably with each addition of 2000 data points, suggesting that with additional resources and a larger dataset, our model architecture could achieve competitive results.
Key Learnings and Future Work
Machine translation of American Sign Language (ASL) remains an ongoing challenge. This project presents a new architecture for the translation of ASL comprised of a fine-tuned MoViNets CNN model to produce video embeddings and a fine-tuned T5 encoder-decoder model to generate translations from the video embeddings. Using this architecture, our model achieved results comparable to state-of-the-art solutions despite operating with a smaller dataset. Further training of the model presented here on a larger data set would be a natural progression to evaluate its efficacy. A significant limitation of this architecture is the large size of the MoViNets model, which runs slowly and therefore may not be practical for live-translation. Exploration of smaller architectures for the CNN component in future work would help alleviate this shortcoming.
A significant focus should be on reducing the model's processing time, a current challenge due to the complex nature of the models and the video data. Implementing quantization will be a crucial step in optimizing the model for faster responses. Moreover, adapting the model with a lighter CNN architecture will facilitate quicker inference and enable deployment on mobile platforms like iPhone and Android.
Ensuring inclusivity in the resulting product is vital. The model's performance needs to be assessed across various demographic groups to ensure it serves a diverse range of ASL signers effectively and fairly. These steps are crucial in advancing our project to make ASL translation more accessible and reliable.
Acknowledgements
The research in this project benefited considerably from several discussions with our instructors. We gratefully acknowledge Mark Butler, Cornelia Ilin, and Zona Kostic, for their unwavering guidance both during and outside of lecture. We also thank the providers of the YouTube-ASL, WLASL, MS-ASL, and How2Sign datasets, which were used in our modeling efforts. Additionally, we would like to give our heartfelt thanks to Amanda Duarte, Laia Tarrés Benet, Dan Kondratyuk, Jenny Buechner, Kira Wetzel, and Danie Theron for their support during the various stages of this project.