









PERC: Personal Trip Planning Recommender
Problem & Motivation
PERC is a website that helps people plan trips by recommending activities in their destination city. PERC does this by having users select activities that they enjoy in their home city, and then presenting similar activities in the destination city. This is a helpful way to travel plan because users can find activities that fit their unique interests without having to review travel planning books/media. Lastly, we offer methods to route plan between multiple recommendations by integrating with Google Maps.
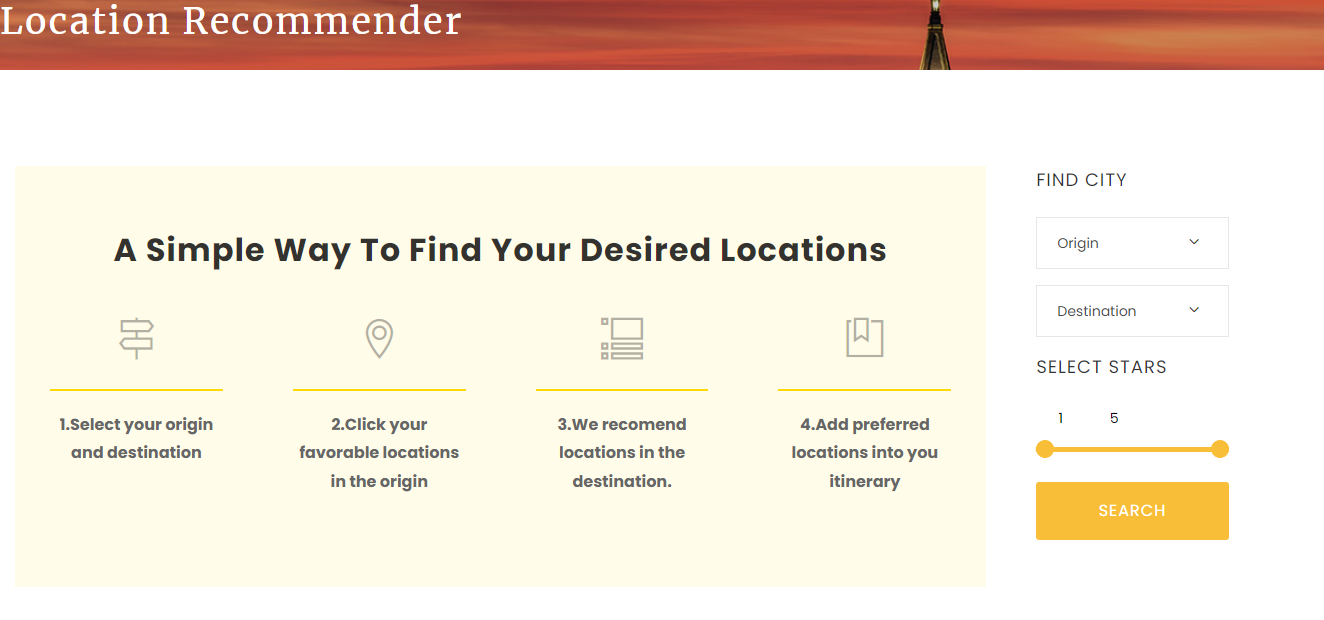
Feel free to view our website and try it out. There are 4 simple steps detailed below and on the main page of the website. PERC
Data Source & Data Science Approach
To create PERC, we used data from the Yelp Open Dataset. This dataset contains ~7 million reviews on ~150 thousand businesses. To enable PERC to make recommendations, we've trained a couple of models and averaged the results to select similar businesses across cities. All of our models start by processing the reviews of each business with basic Natural Language Processing techniques. Our first model then collects keywords for each business, topics for each business, and does sentiment analysis on the business' reviews. These measurements are used to calculate a cosine similarity between each business so that we can tell how similar businesses are. The second model groups reviewers based on their reviews of activities, calculates how much each business fits these groupings based on the reviews of the business, and then predicts which businesses are most similar using these scores. When a PERC user selects a business that they like, we average the rankings of similar businesses from these two models to produce final recommendations of similar activities.
Evaluation
Predicting how similar businesses are too each other is not a cut and dry classification problem where there is a defined right and wrong answer. It is therefore slightly harder to evaluate how successful our model is. One of the ways that we're evaluating the model is to take users who have reviewed multiple businesses, seperate some of their reviews into a test set, and then predict a user's star rating of the businesses in the test set based on their grouping in our second model. Using this technique, our model estimates the star rating with a Root Mean Squared Error of 1.2.
Perhaps the best way to determine if the model is working though is to get in the website and see if it is making good recommendations. We've had some promising results here. For instance, if comparing businesses in Philadelphia, the recommendations that come from selecting Lincoln Field are The Philadelphia Eagles, Wells Fargo Center, Rivers Casino Philadelphia, Love Park, and Citizen's Bank Park. 4 of these recommendations are sports related, which is a big part of Lincoln Field's entertainment, and we feel pretty good about these recommendations.
We've definitely seen some odd recommendations though. For instance, if a user is comparing activities in New Orleans to activities in Philadelphia and they select that they like Burbon Street (New Orleans) our model will recommend the Rocky Statue (Philadelphia). This kinda makes sense because both options are popular tourist attractions, but besides that they have little in common. If the user selects the Mutter Museum, a museum about the human body, in Philadelphia and looks for similar activities in New Orleans, they'll get recommendations for a street car, a bar, and a haunted history tour. This example suggests that the model has some gaps.
Key Learnings and Impact
Our key learning is that because recommendation systems don't have a "ground truth" like classification problems, we need to create a system to view and evaluate model outputs as quickly as possible. Prototypes enable rapid iteration and we sped up development and improved performance once we had one.
Acknowledgements
We have to thank our advisors Joyce Shen and Fred Nugen for providing consistently insightful feedback throughout our project.