

 Saxenian")






CellViT: Accelerating Drug and Biomarker Discovery with Cell Painting and Vision Transformers
Problem
Today, nine out of ten drugs fail in clinical trials. Furthermore, it takes over a decade and an average cost of $2 billion to develop and approve each medicine.
An important underlying reason is the gap that exists between cell-based in vitro research and clinical research—often referred to as the “valley of death.” Promising in vitro candidates often fail in the clinic, as in vitro models turn out to be insufficiently predictive and translatable to the clinical setting.
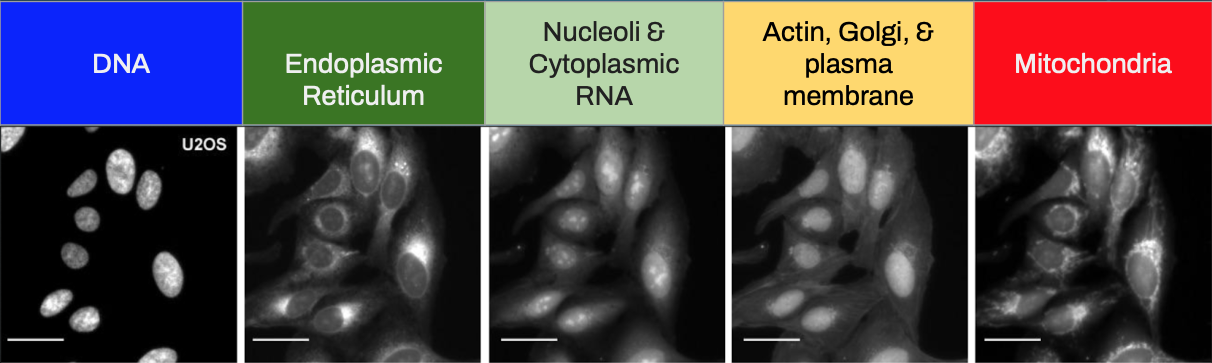
Cell Painting is a high-content, multiplexed image-based assay used for cytological profiling. These image profiles can be used to identify the mechanism of action of novel drugs by comparing the induced morphological profile with the profiles of reference compounds or gene expressions.
In a Cell Painting assay, up to six fluorescent dyes are used to label different components of the cell including the nucleus, endoplasmic reticulum, mitochondria, cytoskeleton, Golgi apparatus, and RNA. The goal is to “paint” as much of the cell as possible to capture a representative image of the whole cell.
Mission
Through the use of a transformer-based neural network, we aim to significantly boost the performance of cell-painting assays and help accelerate therapeutic target & biomarker discovery efforts in drug development.
Project Objectives:
- Accurately classify cell treatments applied (chemical & genetic)
- Improve classification accuracy beyond the convolutional neural network-based method (current best-in-class approach)
- Provide a pre-trained MaxViT model specific for cell painting images for community use
Data Source
The Cell Painting Gallery is a collection of cellular image datasets created using the Cell Painting assay.
The images of cells are captured by microscopy imaging, and reveal the response of various labeled cell components to whatever treatments are tested, which can include genetic perturbations, chemicals or drugs, or different cell types. The datasets can be used for diverse applications in basic biology and pharmaceutical research, such as identifying disease-associated phenotypes, understanding disease mechanisms, and predicting a drug’s activity, toxicity, or mechanism of action (Chandrasekaran et al., 2020).
This collection is maintained by the Carpenter–Singh lab and the Cimini lab at the Broad Institute. A human-friendly listing of datasets, instructions for accessing them, and other documentation are on the corresponding GitHub page about the Gallery.
We used roughly 27,000 single-cell images from the BBBC037 image set within the cpg0019-moshkov-deepprofiler Cell Painting Gallery dataset (Moshkov et al., 2022). The images were uniformly distributed across 13 classes. Each class represented a distinct genetic perturbation of U-2 OS cells. U-2 OS cells are osteosarcoma cells derived from the tibia of a 15-year, White, female patient in 1964.
Modeling & Evaluation
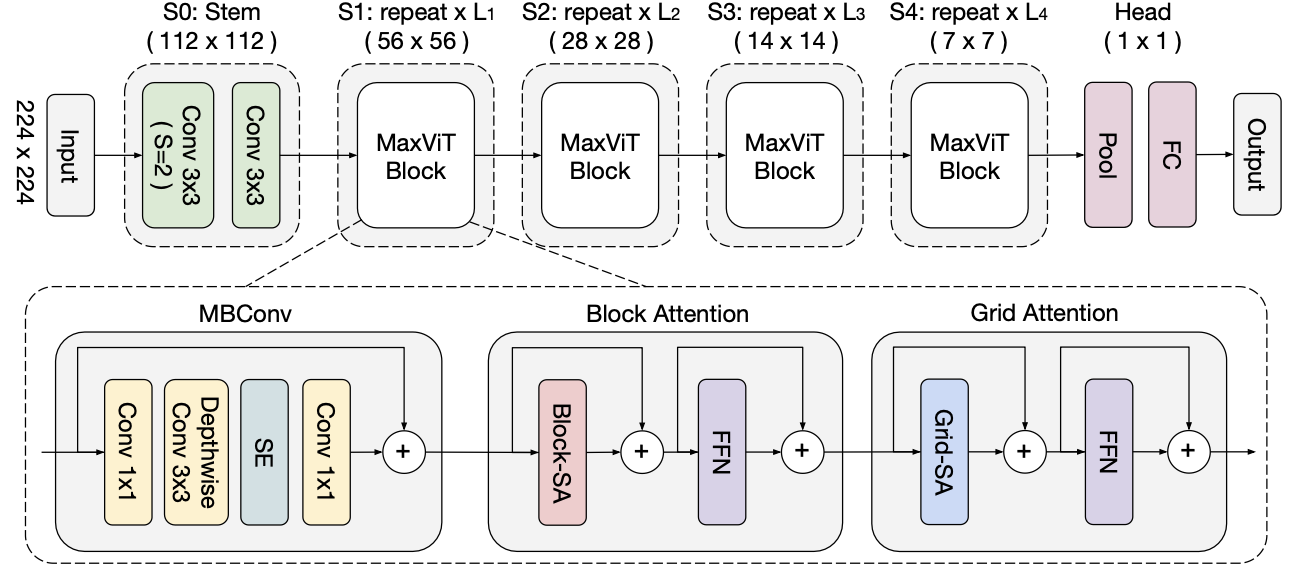
CellViT is a fine-tuned model based on MaxViT, a family of hybrid (CNN+ViT) image classification models that achieves better performance than both SoTA ConvNet and Transformer models.
In the past, the only deep learning architecture used on these images was a pure convolutional neural network. Over the last two years, nearly all new state-of-the-art image classification models on ImageNet have been vision transformer models. This is the first time a vision transformer has been applied to images generated from the Cell Painting assay. We chose to work with the Multi-Axis vision transformer architecture released last year by Google Research and The University of Texas at Austin.
The multi-axis vision transformer is built by stacking individual MaxViT blocks between the network’s stem and head layers. Each MaxViT block is made up of three components: 1) a mobile bottleneck layer from MobileNetV2 (also the basic building block of EfficientNet architectures), 2) the local, block attention mechanism, and 3) the global, grid attention mechanism.
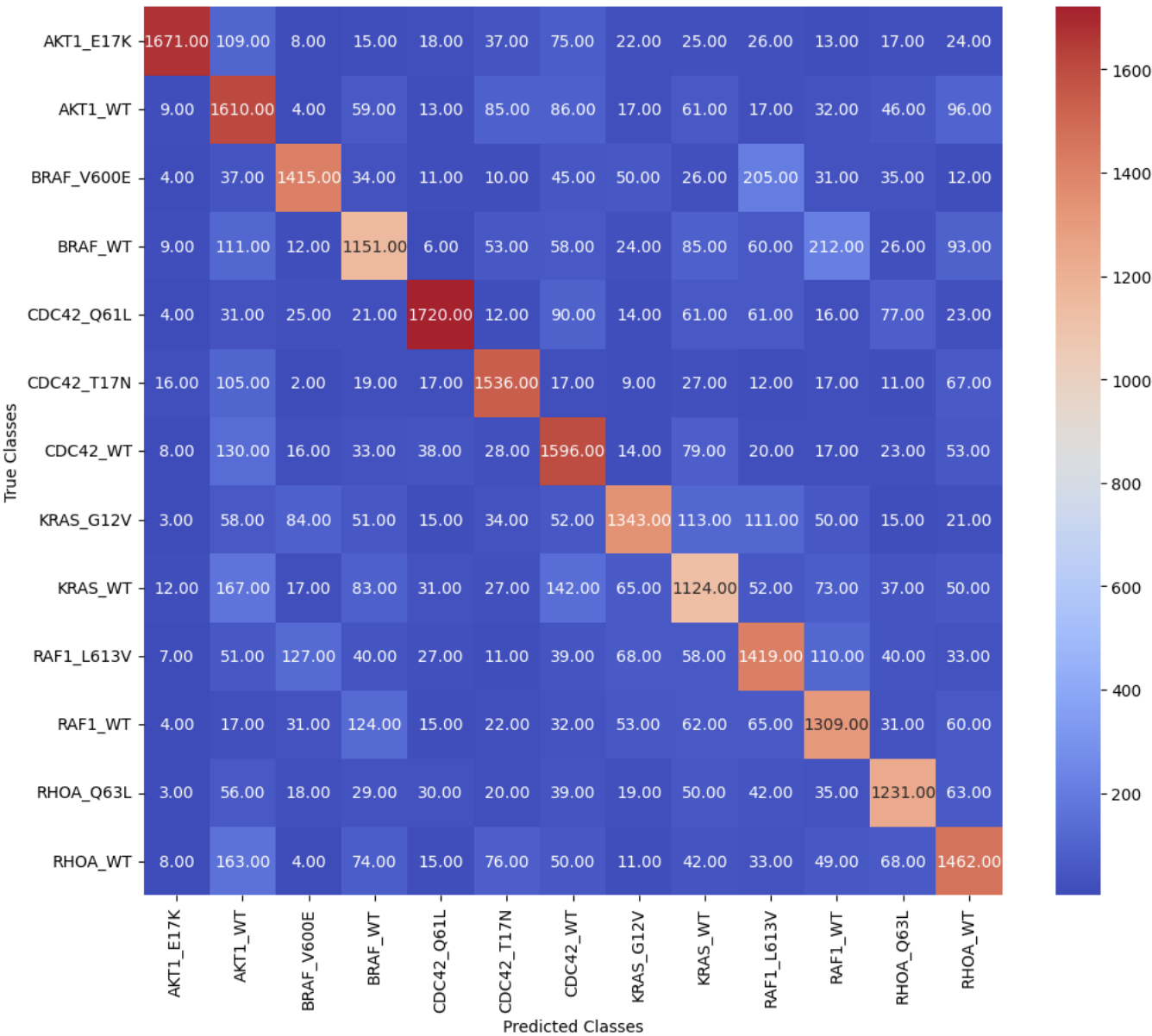
We observed a Top-1 accuracy of 73.03% and an F1 score of 73.18% on the twenty percent of images heldout in the validation set.
An important aspect of our results is that when the model's class prediction differs from the true class, the predicted class is typically of a gene or allele in the same gene family as the true class. The model's ability to identify genetic perturbations with similar morphological phenotypes can be used by researchers working to understand biological pathways of novel chemical compounds.
Acknowledgments
Special thanks to...
- Joyce Shen & Fred Nugen (project advice & capstone guidance)
- Brittney Van Hese, Recursion
- Matt Chang, Loxo Oncology@Lilly
- John Moffatt, Genentech
Course
Data Science 210. Capstone , Spring 2023