

 Saxenian")






Pharmalytics: using computer vision to improve pharmacy operations and save lives
Pharmalytics: Reducing Preventable Medication Errors
The medical system fails to uphold the hippocratic oath for the thousands of patients that suffer from preventable medical errors. At least 7,000 Americans die from misfilled medications that are prepared in a largely manual process in pharmacies around the country. Pharmalytics is on a mission to ensure that patients receive the correct medication everytime they fill a prescription. With our technology, we're turning the tide against preventable medication errors and paving the way for a safer, more reliable future in pharmaceutical care.
We are doing this through a computer vision model that verifies the count and drug of each prescription. Our solution only requires a cell phone with camera, ARUCO code background, and internet access to http://vispillid.com:8000/index.html.
Data Source & Data Science Approach
Data
This project used three distinct datasets: EpillID, Pillbox, and Pharmacy. The first two datasets are from the National Institutes of Health, having 21k images of pills. The data from these sources had a wide range of quality and metadata for pills. Distinct to these datasets is that there were at most two pills per image, one of the front and one of the back of the pill. The pharmacy dataset was collected in partnership with local pharmacies and this allowed us to collect photos with numerous pills. All of our final testing data came from the pharmacy dataset. Over 500 photos were taken of 102 unique drugs in a pharmacy setting. Since there are a limited number of photos for each class we are training on, we were required to create many augmented images of each pill so we can simulate various lighting conditions, rotations of pills, and quality of images. The image segmentation model utilized Roboflow to train a YOLO model. This required the hand annotation of over 2,000 images.
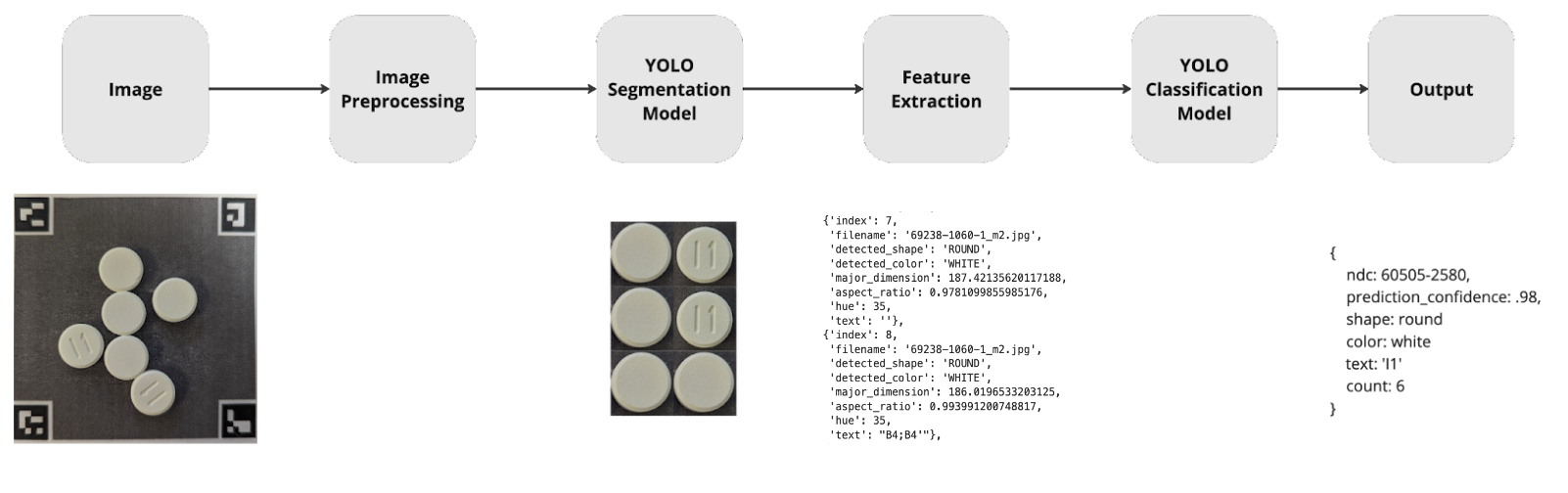
How it Works & Model Architecture
Pills are placed on the grey background with ARUCO codes and uploaded to our website. The grey background with ARUCO codes allows us to perform some image preprocessing like correcting for lighting. This image is sent to the YOLO segmentation model and an image is created for each pill. These individual pill images undergo feature extraction where color, size, shape, color and text are determined. The segmented images are sent through a YOLO classification model that generates a list of suggested classes that correspond to medications that we have trained on. Each image's features and suggested classes are consolidated and reduced to a singular prediction and count of pills.
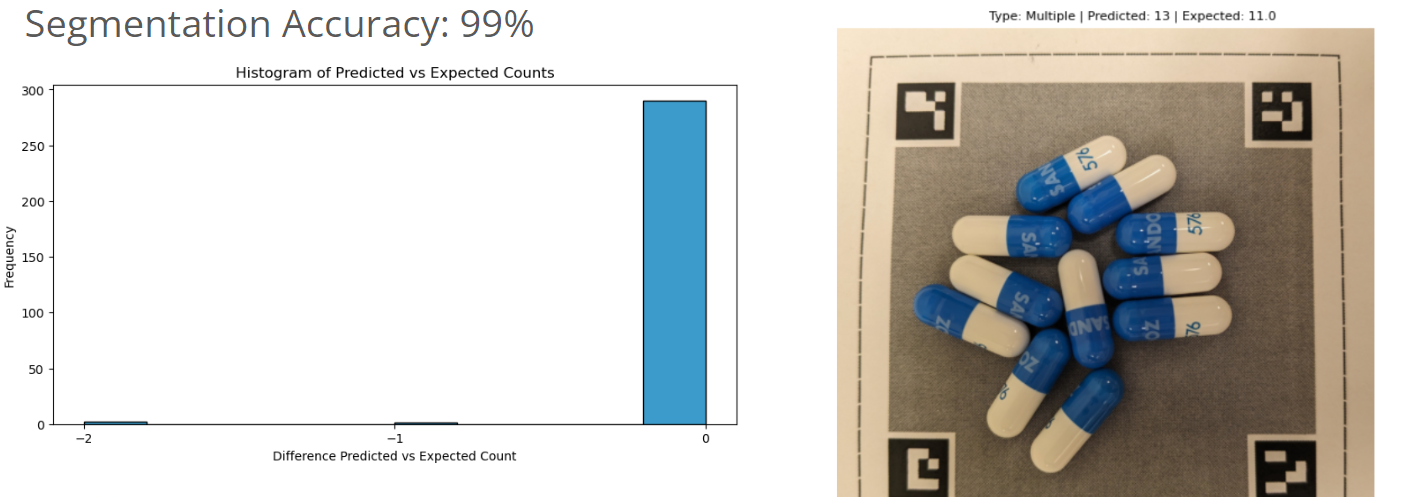
Evaluation
There are several models that are used to create the final identification and count of a given prescription image. For segmentation we are evaluating accuracy across 300 multiple pill photos, yielding a 99% accuracy. This model tends to over count capsules with multiple colors. These results are shown below:
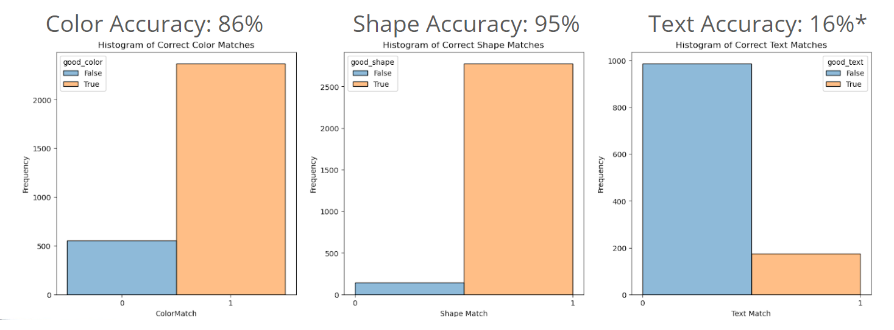
For feature extraction of color, shape, and text, accuracy was the key metric that we optimized for. Color and shape we were able to achieve high levels of accuracy but were challenged by extracting text. Easy OCR was used as a basis for this model but our use case was exceptionally difficult for the model to get exact text match. This was due to a number of factors: lighting, text not being rotated, non-standard characters, poor contrast due to embossing of text, and capsules displaying only a portion of the complete text. Below are the results of these models:
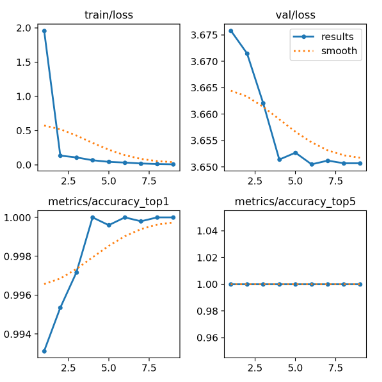
The YOLOv8 classification model that was trained on our large training dataset showed exceptionally strong performance with nearly 99%+ accuracy. This is similar to what was shown in previous studies that were training and testing on images of single pills in ideal conditions. Results below:
Although the results of this model were quite good, it did not translate into real-world performance. Our approach to consolidating the results of the classification of every segmented image in a photo yields a nearly 70% accuracy on real-world photos of prescriptions.
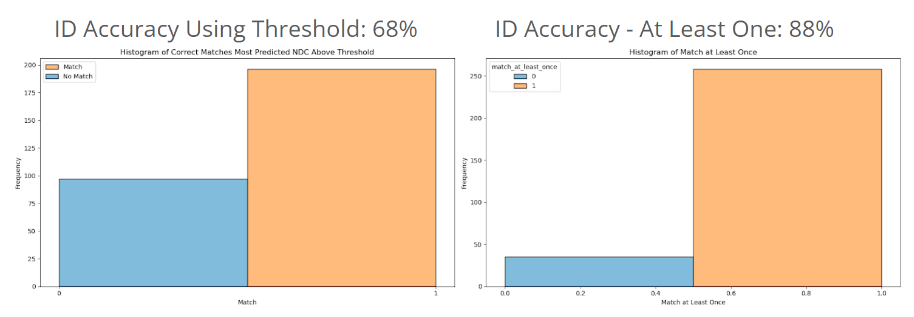
Key Learnings & Impact
Our minimum viable product has shown that it is possible to accurately identify and count prescription medications utilizing our approach. Using a naive approach to consolidating the data gathered from segmented images is foundational to demonstrating the potential of this project. Continuing this work by refining how data is consolidated, we believe that we can get close to human levels of performance in this domain. The key barriers to higher levels of accuracy in real-world photos is the following:
- Controlled lighting and photo consistency provided by a workstation prototype
- Advancing the text recognition approach to be able to manage embossed text on pills of any orientation
- Improvement on image segmentation to produce ‘smoother’ images of individual pills
Pharmacists were shown this minimum viable product and they believe with the development of an app or workstation this product can significantly aid pharmacy operations and improve patient care.
Acknowledgements
We would like to thank the partners at Bonita Family Pharmacy, San Antonio’s Pharmacy at Casa Colina. In particular thanks to Lyn Luu and Darren Roura for their guidance and help in collecting real world test photos.
Course
Data Science 210. Capstone , Spring 2024