

 Saxenian")







EchoBrief
Problem and Motivation
Busy students and professionals have limited time to keep up with the dynamic world of technology, and fireside chats with tech leaders are a treasure trove of knowledge. However, these podcasts can be challenging for students who are not native English speakers. The combination of technical jargon, complex ideas, and the pace of the conversation can make it hard to follow and extract the most important points. EchoBrief bseeks to empower these students by making these resources more accessible. With concise summaries and translations into their preferred language, the tool helps them navigate the insights shared by industry leaders.
Data Source & Data Science Approach
Our project leverages large language models (LLMs) to summarize long-form podcasts, focusing particularly on the technical discussions featured in the Lex Fridman Podcast, which averages two hours per episode. This approach is designed to distill extensive audio content into concise, comprehensible summaries that are easier to consume and more time-efficient for our audience.
Methodology
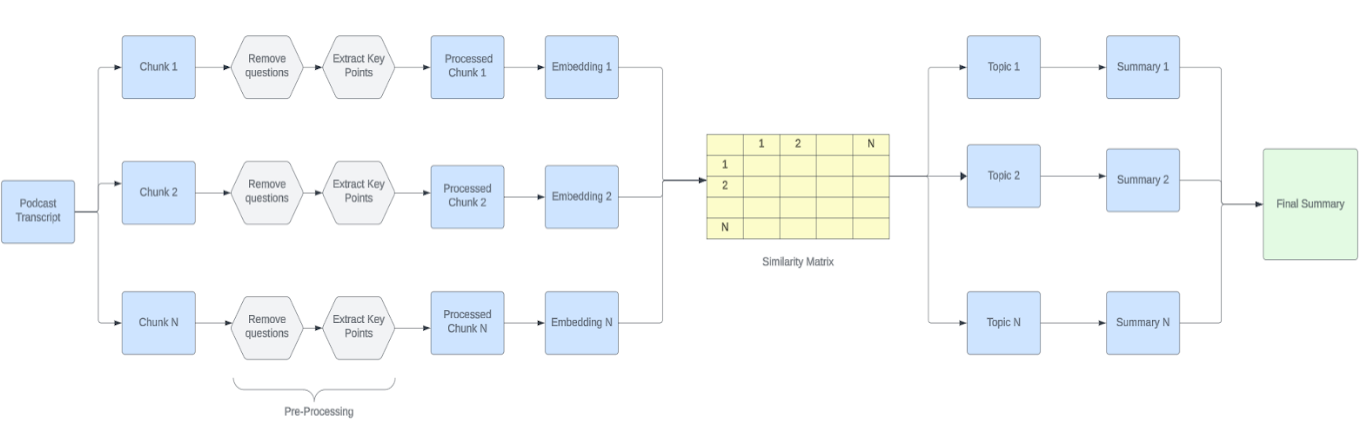
The process of generating summaries involves several key steps, utilizing both proprietary and open-source technologies:
- Chunk Creation: To address the extensive length of the podcasts and overcome the token limitations of LLMs, we begin by splitting the transcribed text into manageable chunks. The LangChain Text Splitter is employed here, a tool adept at dividing large text bodies while preserving contextual continuity.
- Pre-processing of Chunks: Each chunk undergoes targeted pre-processing to refine the content, focusing specifically on extracting key points and relevant answers while omitting questions. This step ensures the removal of extraneous elements, such as redundant questions, which do not contribute to the essence of the discussion. The goal is to enhance the clarity and density of information in the summaries, maintaining consistency and relevance throughout the dataset.
- Chunks to Embeddings: Using a state-of-the-art LLM, we convert the processed chunks into embeddings, which capture the semantic essence of the text in a high-dimensional space.
- Embeddings to Topics: These embeddings are subsequently clustered using the Louvain Algorithm, a community detection technique that identifies prevalent topics within the text.
- Topics to Summaries: For each identified topic cluster, we generate summaries through the LLM, ensuring that each summary accurately reflects the core topics discussed within the chunk.
Multilingual Support
To broaden the reach of our summaries to non-English speakers, we integrated the Amazon Translation API. This allows for the automatic translation of our summaries into multiple languages, enhancing accessibility for a global audience.
Evaluation
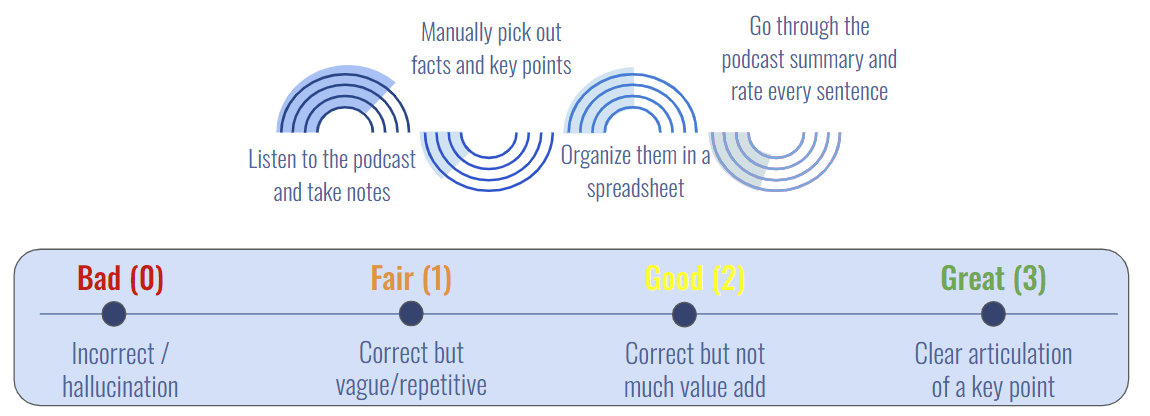
We utilized both machine and human evaluation methods to assess podcast summaries generated by our model pipelines. For machine evaluation, we employed BERT score to compute the cosine similarity between generated summaries and their corresponding full transcripts. Additionally, we utilized Named Entity Recognition (NER) score to ascertain the extent to which a generated summary has captured information ("entity") present in the original transcript. Human evaluation entails a manual process established for team members to assess summaries with minimal subjectivity. The process involves extracting facts and key points from the podcasts through listening and transcript reading. Subsequently, facts and key points are selected and organized into a spreadsheet for evaluation. A 4-category rating scale (Bad/Fair/Good/Great), along with category guidelines, has been established. This rating scale enables objective assessment of each sentence in the summaries. A final score is then calculated by averaging the rating scores from all sentences in a summary. Furthermore, we devised a key-point score to determine the presence of important key points in a summary. Ultimately, these machine and human evaluation scores are utilized to determine which set of model pipeline hyperparameters perform optimally.
Impact
Summaries allow users to quickly grasp the core concepts without struggling through dense audio content. Translations break down the language barrier, ensuring full comprehension of the ideas and terminology used by tech leaders. This combination supports deeper learning, allowing students to benefit from these valuable resources despite potential language limitations.The market for such a tool is promising. Students worldwide are increasingly interested in technology fields, and there's a need for solutions that cater to non-native speakers. By focusing on summaries and translations, this tool can capture a significant audience that other podcast-related resources might overlook.
Acknowledgements
We would like to express our sincere appreciation to our course instructors, Joyce and Korin, for orchestrating the course content and providing invaluable feedback.
We extend our gratitude to our project Subject Matter Experts, Dr. Deb Donig, the host of Technically Human Podcast, and Mary Park, the host of Sounds of Science, for their insights and support throughout the development process.
Course
Data Science 210. Capstone , Spring 2024More Information
