

 Saxenian")







Fake News Bears
Problem
Media disinformation has the power to negatively impact countless lives and is often used to marginalize at-risk members of the population. It can spread like wildfire and the detection of fake news is often not simple. Our goal is to spread awareness and increase education by creating easy-to-understand scoring mechanisms for influential Twitter users' content.
Mission
Fake News Bears is focused on educating individuals about their exposure to and engagement with disinformation online which affects social media users worldwide. Using historical tweets from US politicians’ Twitter accounts, we apply existing disinformation detection and contextual models to calculate an aggregate score evaluating a politician’s Twitter account. For our MVP, we provide custom educational information on why that politician received a given score and the top three tweets that contributed to it.
Data Sources
Our product's dataset contains approximately 500,000 tweets published between 2022-2023 from 485 US Congress members. To collect the latest 100 tweets per politician, we created pipelines to extract this data using the Twitter API, and for historical tweet data, we used our partner Torch’s platform to extract tweets in CSV files. The politicians’ metadata including their Twitter handle, party affiliation, political office, and state/district was pulled from secondary sources including Press Gallery House and UC San Diego.
- US politician metadata
- Includes fields like Twitter username, political party, political office, etc.
- Twitter profile user data
- Includes fields like Twitter user id, follower count, number of posts, account creation date, etc.
- Twitter tweet text data
- Includes fields like Twitter user id, tweet id, tweet text, like count, retweet count, etc.
Below is an example of a tweet that could come from one of our data sources:
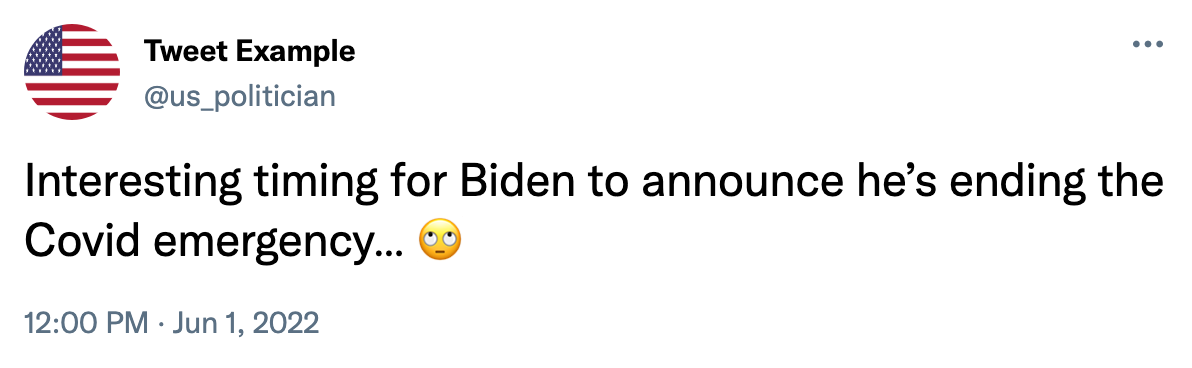
Using the techniques listed in the image above, text from tweets was cleaned up in order to run inside the pre-trained models. Non-standard symbols were trimmed and contents such as links and common stopwords were removed from the corpus. Lastly, different variations of the same word were lemmatized so that they were evaluated the same way in the models. Ultimately, the cleansed version of the tweet example above would look like this:
[“interesting”, “time”, “biden”, “announce”, “ending”, “covid”, “emergency”]
Our Product
The goal of our product is to educate social media users on US politicians' impact on the spread of disinformation on Twitter through an individualized, interactive, and informative platform experience. Our product features three main steps including tweet collection, model application, and custom reporting. Users can access our team's Tableau Public dashboard to view and compare any US Congress member's Twitter profile and learn more about the content they share online.
Modeling & Evaluation
We incorporated existing research on detecting truthfulness and sentiment with large language models into our pipeline to score tweet content. We used a total of eight pre-built models including three models for detecting the truthfulness of tweets and five sentiment models for detecting the emotions evoked by tweets:
- LSTM: Truth
- Dense: Truth
- Cardiff: Irony
- Cardiff: Offensive
- Cardiff: Hate
- Cardiff: Real
- Cardiff: Joy
- Cardiff: Anger
Our models present a promising start in terms of sentiment and text analysis, as well as highlighting potential shortcomings and challenges to overcome in future iterations. While they perform strongly in detecting the negative sentiments of hate, irony, and offensiveness of tweets, there is much room for improvement when it comes to truth detection. Part of this discrepancy can be explained by the difficulty in rating the truthfulness of many statements (i.e., evident in the person-to-person score differences), and another could potentially be chalked up to the limited body of text that is present in tweets.
Key Learnings
Some of our technical key takeaways include:
- Pre-processing tweets is painful and requires significant cleansing to ingest data
- Extracting data from Twitter’s API has changed and requires significant rate limiting
- Human evaluation is trickier than it seems especially for short-form texts
- Sentiment and truth analysis can vary over time and between manual graders
In future iterations, we hope to include the following in our product roadmap:
- Apply more diverse models for evaluating truthfulness (i.e., URL and image processing)
- Further develop unsupervised learning and cluster users to identify patterns and trends
- Build an end-to-end pipeline that enables users to score their own Twitter account and learn about their impact on the Twitter-sphere
Limitations
Our team’s intention for building this product is to educate social media users, but we must acknowledge that it has the potential to be used in ways that go against our mission and values. The models we use to score tweets on truthfulness and sentiment have limitations and possible biases as they are only as good as the data they were trained on. While we strive for accuracy, there are limitations to these methods, including variations in the interpretation of language and the subjective nature of determining what constitutes "fake news." Therefore, the scores should be taken as indicative rather than definitive.
This project aims to (1) inform Twitter users about the content that politicians are sharing on the platform and (2) inform politicians about how they might be contributing to the spread of fake news. We strongly advise our viewers to review our website's "Our Product" section for how to critically interpret and evaluate the results of a given politician. When in doubt, please feel free to reach out to anyone on our team and we would be happy to help.
It is essential to use these scores alongside other sources of information (such as FactCheck.org or Politifact.com) and critical thinking to make informed decisions.
Acknowledgments
Special thanks to...
- Joyce Shen & Zona Kostic (project advice & capstone guidance)
- Levi Braslow, Purpose Campaigns (product direction & recommendations)
- Mike Seiler, Torch (Historical Twitter data of US politicians)
- Mackenzie Austin, Bronte Baer, Noriel Bargo, Ben Bluhm, Coco Cao, & Bronte Pendergast (W231 capstone audit)
Course
Data Science 210. Capstone , Spring 2023More Information


