

 Saxenian")






Story Sprout
Overview
Story Sprout is an AI-powered storytelling platform designed to help children and their caregivers turn imaginative tales into fun, personalized coloring books. Whether you're a young writer with a big idea or a parent looking to nurture your child’s creativity, Story Sprout offers a safe, collaborative space where stories come to life one page at a time.
Using the Coloring-Book-Flux-LoRA model from prithivMLmods, Story Sprout generates high-quality, consistent illustrations based on your story’s characters and settings. Kids drive the storytelling process with their own words and ideas, while AI plays a supporting role turning their imagination into visual art.
Unlike most AI tools that generate a single image, Story Sprout supports multi-page stories, complete with recurring characters and evolving scenes. With kid-friendly narrative writing guidance, Story Sprout also encourages literacy skill development and visual thinking in a fun, intuitive environment.
We believe that every child deserves to see themselves in the stories they tell. That’s why our platform prioritizes diverse, inclusive character generation and customizable traits, so kids can create heroes who reflect their identities and experiences.
Whether you're working on a bedtime story, a classroom activity, or a rainy-day adventure, Story Sprout blends creativity, technology, and education into an experience that feels magical. Story sprout is powered by tech, but driven by imagination.
Motivation
Kids today are digital natives. Growing up surrounded by screens, they are spending more time online than ever before (BackLinko, 2025). That increased screen time isn’t inherently a bad thing, but at the same time, more than 60% of elementary students aren’t reading at grade level (National Literacy Institute, 2025). This begs the question: how are kids spending their time online? There seems to be a growing disconnect between the ways children are engaging with technology and the ways we want them to engage—with curiosity, imagination, and agency. The majority of apps and digital tools available to kids are focused on passive entertainment, generating content for them, not by them. We wanted to flip that model.
We created Story Sprout to transform screen time into a meaningful space for creativity, connection, and learning. Our motivation is simple: to grow confident readers, bold creators, and curious thinkers one page at a time.
Our Solution
Story Sprout is an AI-powered storytelling platform that transforms kids’ ideas into vibrant, personalized coloring books. Designed for children and their caregivers to use together, Story Sprout encourages active screen time, co-creation, and early literacy development in a safe and inclusive digital space.
At the heart of Story Sprout is a fine-tuned model built on Coloring-Book-Flux-LoRA (prithivMLmods), enabling the generation of consistent, child-friendly illustrations across multi-page stories. Unlike traditional AI art apps that create one-off images, Story Sprout supports full narratives with recurring characters, evolving scenes, and user-guided story arcs.
Children begin by imagining their characters, settings, and plot. From there, the platform provides kid-friendly storytelling templates with clear beginning, middle, and end sections, offering just enough structure to support young writers without limiting their creativity.
Key features include:
- Consistent characters across pages, maintaining visual cohesion throughout the story
- Diverse and customizable illustrations that reflect a wide range of identities and experiences
- Profanity filtering and child-safe algorithms for a secure, age-appropriate experience
- AI-assisted visuals that support, rather than replace, a child’s own storytelling voice
- Open-source, lightweight design for classroom and at-home use
Story Sprout is more than just another AI tool: it’s a creative literacy lab, designed to help kids build confidence in their reading, writing, and storytelling.
Behind the Scenes
AWS Infrastructure
Story Sprout is deployed using a robust, production-ready cloud architecture powered by AWS. We containerized our Flask web app and orchestrated it with Amazon ECS, ensuring seamless scalability and efficient resource management. A high-availability Application Load Balancer intelligently routes traffic to our containers, while Route 53 powers our custom domain and DNS management for a polished, professional web presence. This end-to-end AWS infrastructure delivers speed, reliability, and a seamless user experience—engineered for growth from day one.
The deployment is fully automated through a CI/CD pipeline built with GitHub Actions, enabling fast, reliable updates with every code push. Story Sprout’s cloud-native architecture empowers us to deliver a seamless experience to users—efficiently, securely, and at scale.
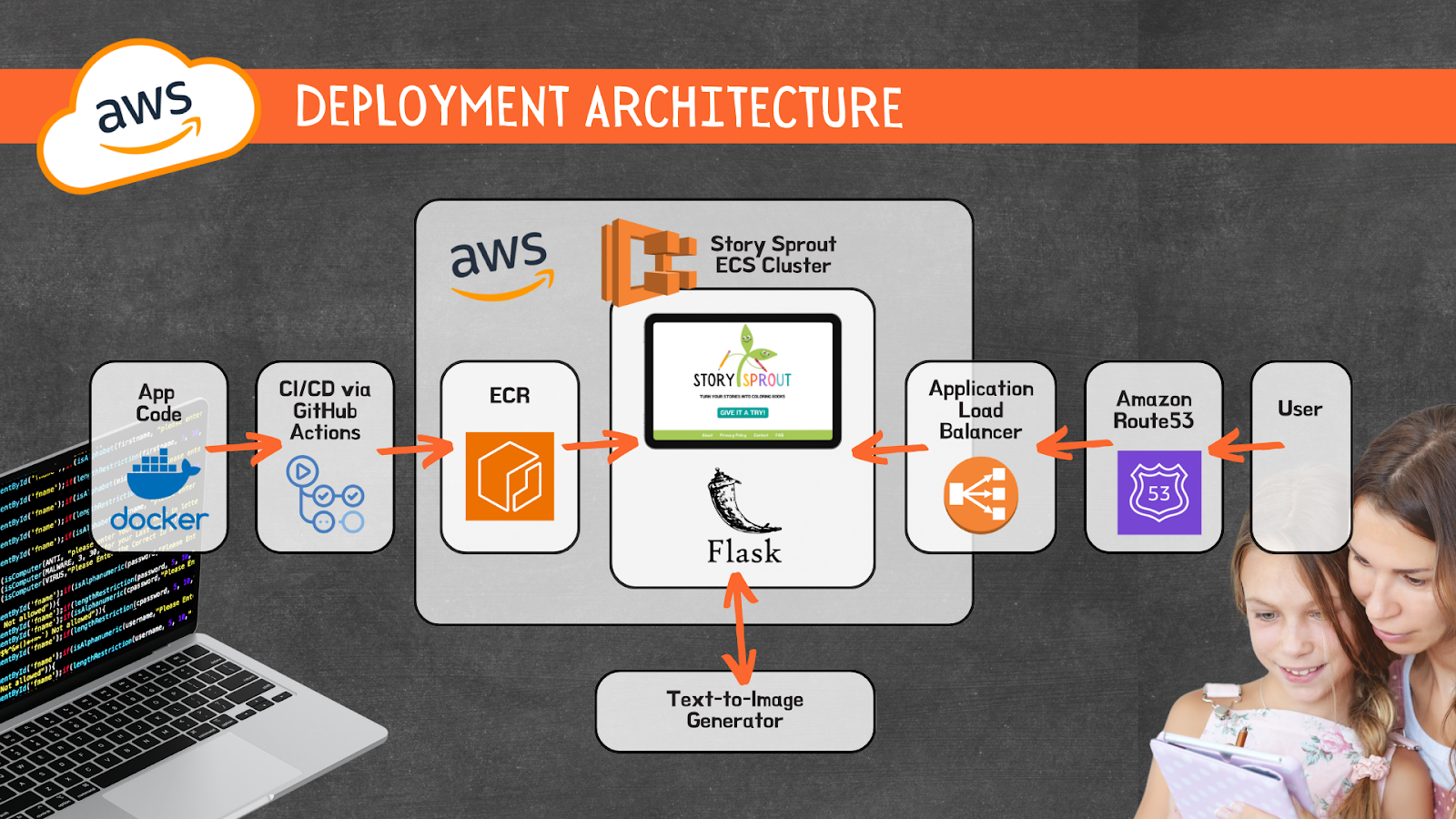
App Flow
Our pipeline begins with structured story inputs: character, setting, and plot, all entered by the user through guided prompts. These inputs undergo a series of validations:
- Profanity Check: We use the Alt Profanity Check python library to scan all editable text fields for inappropriate language. Unlike simple word lists, this model utilizes an ML approach to contextually identify profanity and identify subtle or misspelled profanities. It also outperforms other Python packages in accuracy and recall.

- Recognized Character Attributes: On the character creation page, users must assign attributes to each character using dropdown menus. The recognized character attributes check not only ensures that the user has selected attributes for each of their characters, but it also prevents users from entering developer mode and submitting their own unauthorized attributes.
- Protagonist Selection: Also on the character creation page, we require users to select one and only one main character. This helps us maintain a clear narrative focus and ensures the coloring book centers around a single protagonist.
- First-Person Selection: We query an LLM (ChatGPT 4-mini) with our user defined story and ask it to determine whether or not it is written in first person. If the LLM confirms that the story is written in first person, we scan the character attributes to confirm that a corresponding character has been marked as “this is me.” This ensures correct character mapping when the story uses pronouns like “I” or “me.” We selected ChatGPT 4-mini as our LLM for its fast API response time and ease of integration. We focused our attention primarily on image-generation model selections, though future work could explore comparative performances across different LLMs.
- Setting Selection: At least one setting must be specified for the story to proceed, ensuring there's enough environmental context for our models to generate meaningful imagery.
- Word Count: To balance quality and scope, we enforce a word count maximum of 400 and require at least one complete sentence. We use the python spaCy library to achieve these tasks due to its speed, reliability, ease of use, and NLP parsing capabilities. Our basic use cases did not call for a more customizable option like NLTK. We chose to define a sentence as a “collection of words that starts with a capital letter, contains a subject, verb, and object and ends with a punctuation mark.” We identified the subject, verb, and object of a sentence using spaCy’s language dependency tree.
After the user’s inputs pass all of the validations, the story progresses through the generation pipeline:
- Page Segmentation: Using spaCy, we parse the story into pages based on word count and the objective of not splitting sentences across pages
- Character Assignment & Page Summarization: Each of the separate pages are then individually passed to our LLM (ChatGPT 4-mini) which:
- Identifies which user-defined characters appear on the page
- Summarizes the content of the page in its own words to improve image prompt quality (we found when it comes to writing image prompts later down the line, the LLM does a better job of representing the content on the page if it recieves the content in its own words).
- Image Prompt Creation: For each page, we feed the character list, their attributes, and the page content summary back to the LLM to generate a detailed prompt for image generation.
- Image Generation: The finalized prompts are passed to a fine-tuned LoRA (Low-Rank Adaptation) image generation model. One illustration is generated per page, featuring consistent character appearance and stylistic continuity.
- Final Output: The images are then stitched together with the user’s original story text to form a printable, personalized coloring book. Users can choose to print it immediately or save it as a PDF to color later.

Model Selection
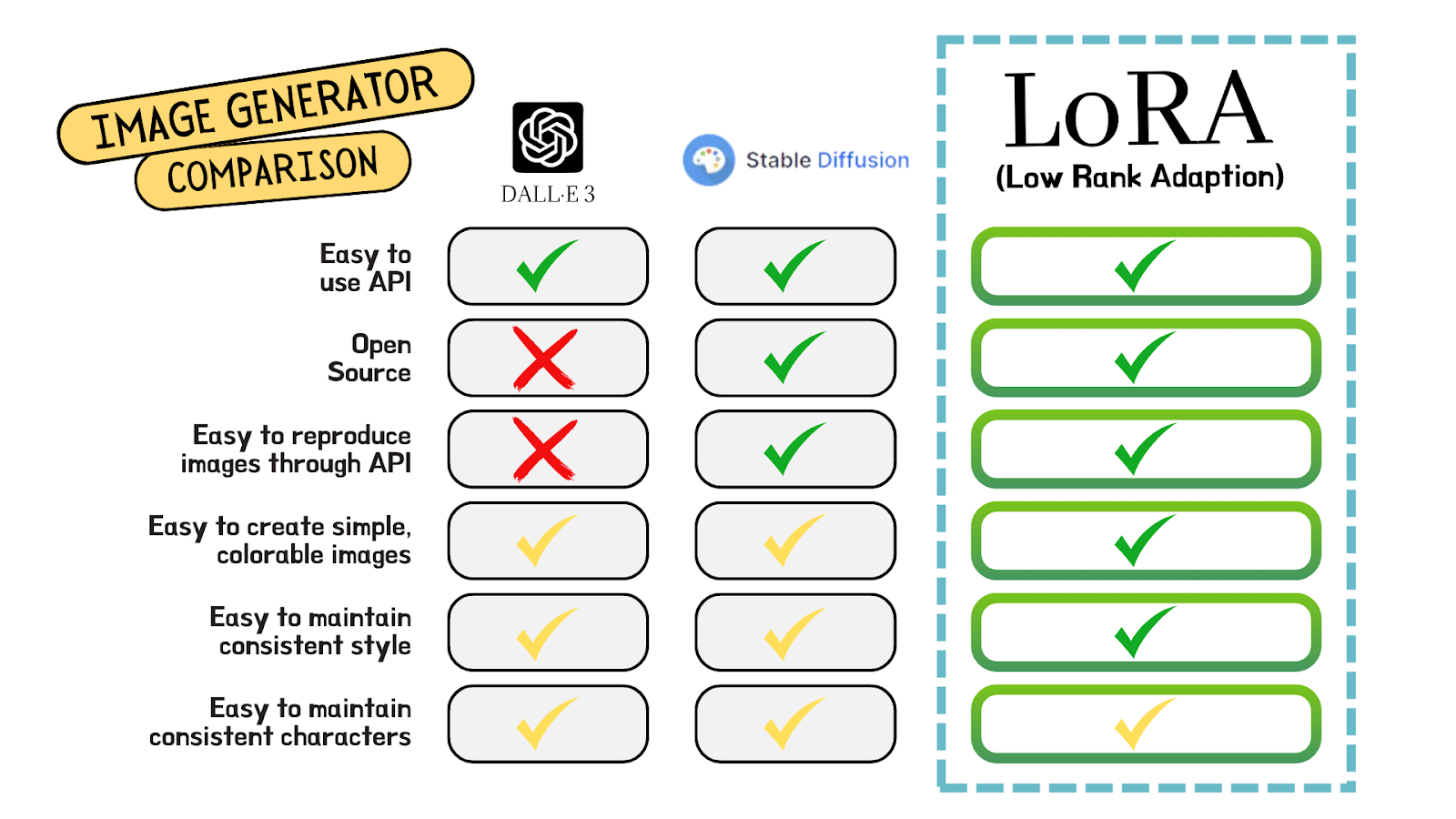
We explored several image generation models, but focused most heavily on three: DALLE-3, Stable Diffusion, and a LoRA fine-tuned model based on black-forest-labs/FLUX.1-dev. Our initial exploration began with DALLE-3, primarily because it offered a generous free tier that allowed us to test a limited number of images each day. This stood out, as most other models require a subscription before you can meaningfully evaluate their capabilities. DALLE-3 also features a straightforward API, making it appealing for quick integration into our project.
However, it quickly became clear that DALLE-3 wouldn’t meet our core requirements. For our MVP, we had three primary goals: generate images that are easy to color, maintain a consistent visual style, and produce consistent human characters. DALLE-3 consistently fell short in all three areas. Additionally, because it’s not open-source, we had no way to fine-tune the model to improve results in these specific domains.
Stable Diffusion was a step up from DALLE-3 in several key areas. Its open-source nature allowed us the option to fine-tune the model to better suit our specific needs, and the ability to generate reproducible images using seed values was a major advantage. However, despite these improvements, it still fell short in our three focus areas: producing colorable images, maintaining stylistic consistency, and generating consistent human characters. As a result, we began exploring alternative fine-tuning methodologies to address these shortcomings.
During our research, we came across a fine-tuning method called Low-Rank Adaptation (LoRA). Originally developed by Microsoft researchers in 2021, LoRA was designed to achieve high-quality fine-tuning results for large language models using only a fraction of the computational resources. Instead of updating full weight matrices during training, LoRA stores updates in lower-rank vector representations, essentially approximating the full weights while still delivering strong performance.
Fortunately for us, this technique has recently been adapted for use with image generation models, specifically to improve continuity in style, subject, or object representation. This adaptation is now publicly accessible through the Diffusers package on Hugging Face. Using this method, anyone can take a robust base model like Stable Diffusion and fine-tune it with just 5 to 10 example images. The result is a custom set of training weights that guide the model to generate images aligned with the desired visual characteristics—whether that's a specific art style, recurring subject, or consistent object representation.
While experimenting with LoRA and fine-tuning techniques, we discovered an open-source model specifically designed to generate coloring book-style images. The model, called Coloring Book Flux Lora, is built on top of the Black Forest Labs Flux base model and was fine-tuned using LoRA for this exact purpose. It aligned well with our goals, producing clean, colorable images in a consistent style. Although it didn’t fully solve character consistency, which still requires complex prompt engineering, it met all of our other requirements, making it the best choice for our needs.
The performance gap between DALLE-3 and the LoRA fine-tuned model becomes especially clear when comparing their outputs side by side. Below are example images generated by each model for the same four-page story. Every step in our ML pipeline remained identical except for the image generator itself. The difference in results is striking.
DALLE-3 struggled across all three of our key criteria. Its outputs lacked visual consistency, showed minimal character continuity, and one page even appeared pre-colored, an issue for a product intended as a coloring book. In contrast, the LoRA fine-tuned model delivered cohesive results: all images share a consistent art style, characters remain visually recognizable across pages, and the illustrations are clean and uncolored.

Model Evaluation
When it comes to evaluating our model, we didn’t focus on how accurately the image generator captured the prompt (since that’s a property of the base model and something we can't change). Instead, we focused on how well our entire ML pipeline was able to generate consistent characters, and how well the app worked for actual users in the field.
Consistency Analysis
To evaluate consistency, we employed a content analysis of generated coloring books using a dataset of 26 stories authored by children. We scored each character trait (age, gender, hair length, hair type, disability, and clothing style) from “1 - Entirely Different” to “5 - Nearly Identical”, checking for visual persistence across each page.
Our final model averaged the following consistency scores:
- Age: 4.7
- Gender: 5
- Hair Length: 4.5
- Hair Type: 4.8
- Disability: 4.3
- Clothing Style: 4.8
User Testing
Story Sprout was deployed for BETA testing to thirteen parents, caregivers, and domain experts. Testers were asked to complete an 11-question survey to better understand the app’s usability, engagement, and educational value.
Our key findings were:
- Nearly half of users reported the image generation process took 5+ minutes (46.2%).
- Over half of all characters remained completely consistent across coloring book pages (55.6%).
- Two-thirds of all settings remained completely consistent across coloring book pages (66.3%).
- All users found Story Sprout to be a productive use of screen time for their little ones (100%).
- All users reported Story Sprout made their children more excited about storytelling (100%).
- All users reported their children enjoyed using Story Sprout (100%).

The usability survey yielded rich qualitative feedback to help us identify the following key areas for improvement moving forward:
- Addressing long run times
- Fine-tuning image prompt generation to improve character & setting continuity
- Developing the model’s ability to generate characters with unique and diverse character traits
- Finding ways to add stylistic variety with images and composition
Future States
In future iterations of Story Sprout, we aim to:
- Employ individual LoRA models for multiple visual styles (e.g., cartoon, anime, comic, etc.) and different character trait combinations to improve the model’s ability to generate diverse characters.
- Allow for character reuse across multiple stories.
- Introduce voice-to-story input for accessibility.
- Increase the number of characters allowed on each page.
Course
Data Science 210. Capstone , Spring 2025More Information
