

 Saxenian")






StepWise: AI Math Tutor
Problem & Motivation
There’s a big difference between how you and I might work together to solve a hard math problem, and how a student might use ChatGPT to solve the same problem. The former is a collaborative process where two people must work together to fill knowledge gaps, complement each other’s weaknesses and strengths, and deliberate to reach a common solution; while the latter is often a copy paste.
Existing AI math tutors are good at solving hard problems, but bad at working together with the students they are designed to teach. There’s a distinct need for an AI math tutor that solicits and depends on real-time human feedback to reach a correct answer to a problem. This way, the AI tutors of the future can operate as peers or teachers: gently nudging students in the right direction without just pulling the answer out of an endless knowledge base.
StepWise is an AI powered math tutoring system that is able to reason step by step for hard math problems and is powered by human feedback. It provides a collaborative system where students can deliberate with the model to fill in knowledge gaps and arrive at a common solution, similar to how collaborative learning with another student or tutor would work. StepWise takes a decision tree approach using the Monte Carlo Tree Search algorithm, allowing users to expand the tree by working with the system to select which candidate nodes for each step of the solution process will be best to get to the final answer. Although the system is mainly trained for high school to undergraduate level math problems, this problem solving methodology can also expand to other domains such as physics or coding, and the human labeled decision trees created from the system can be used to train the next generation of reasoning for AI models.
Data Source & Data Science Approach
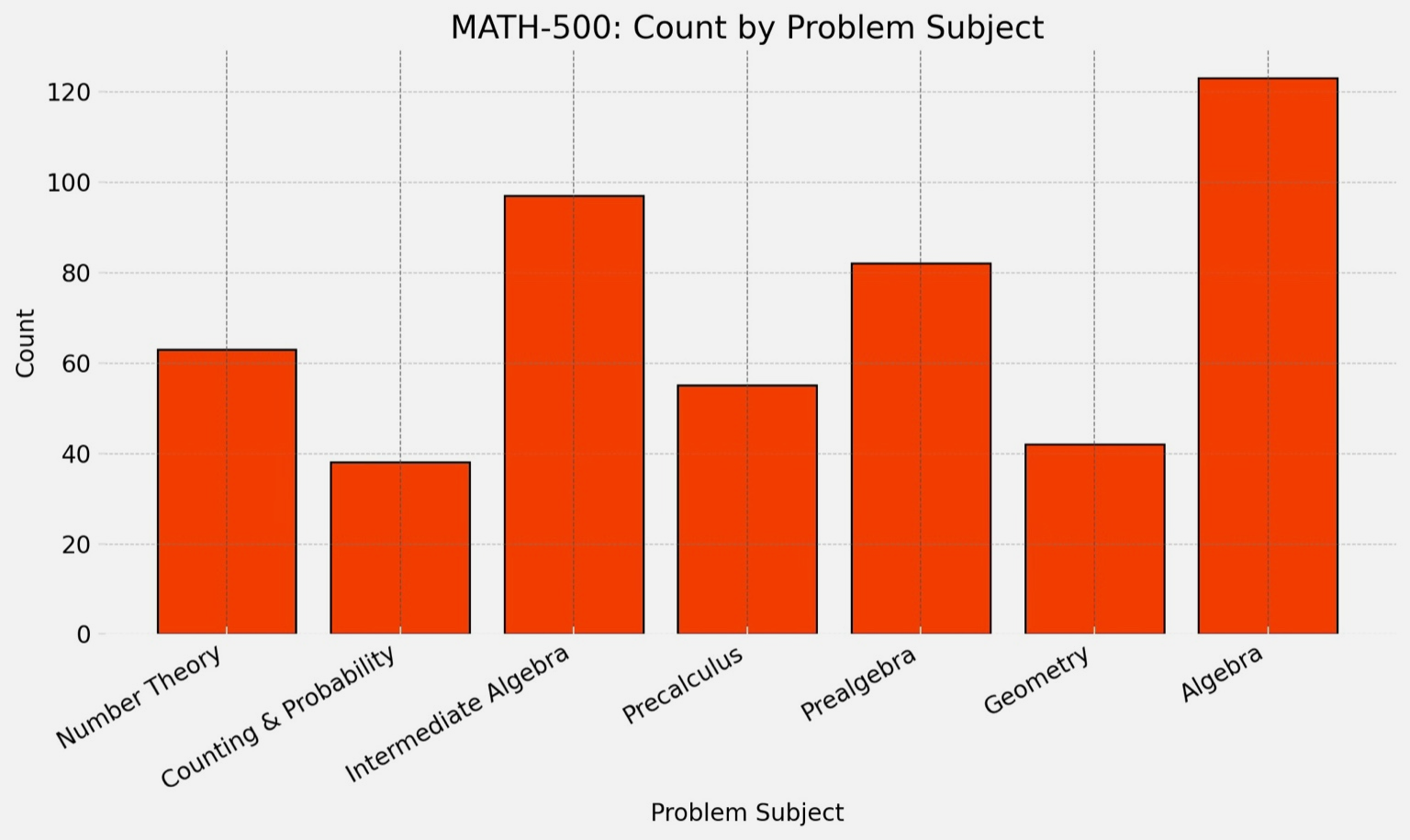
We used the MATH dataset, specifically the MATH-500 dataset for benchmarking. This is a benchmark containing 500 high-school level competition math problems with step-by-step solutions. The dataset covers subjects like number theory, algebra, and geometry, with 7 subjects in total.
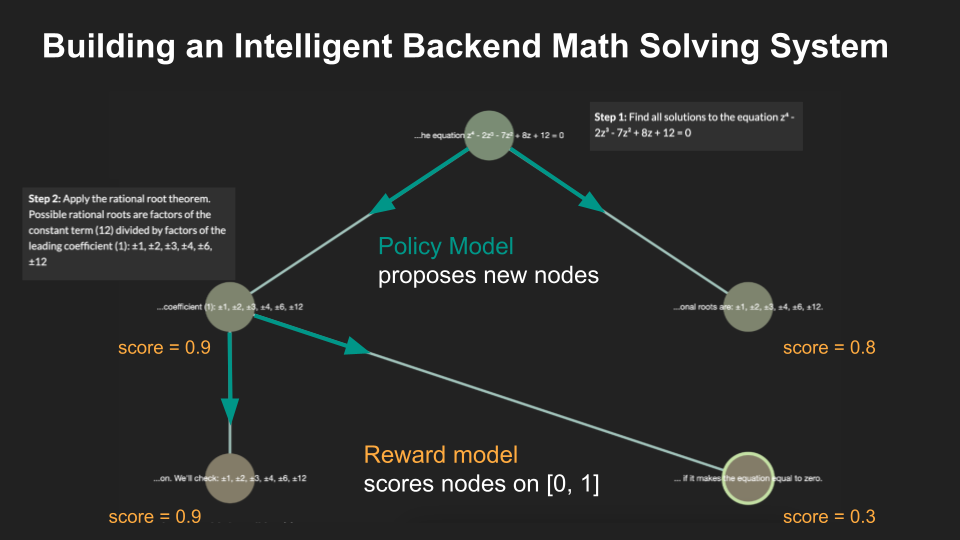
At each step of the interactive reasoning tree, different policy model prompts were used to generate candidate nodes for the next step that the user could either expand, prune, or expand by providing their own human feedback as guidance. The user can tune the difficulty of the tutor to “easy” or “hard”. On “easy” difficulty, a cascading policy prompt would be used to generate distinct candidate nodes that offer different lines of reasoning to solve the problem. On “hard” difficulty, a meta policy is used that combines the cascading policy prompts with adversarial prompts that offer reasoning steps that are subtly incorrect to try to trick the user and make solving the problem a bit more difficult to make sure they are not randomly clicking nodes and expanding an incorrect reasoning path. If the user expands on a node with their own human feedback, an adherent policy prompt is used where only a single node is generated using the human feedback as the prompt. Guardrails are implemented to make sure that personal information is not received in either the problem submission or human feedback and to ensure that only math problems are submitted for the initial input and that any user input for human feedback in expanding a node is related to the current math problem.
The Monte Carlo Tree Search algorithm was used as the backbone of our interactive math problem solving interface as well as a backend solver that could automatically solve the problem and then be used to validate the correctness of the final solution the user reached after solving the problem through the interactive interface. It was used to build a system that efficiently explores the solution space by having each node represent a solution step. Each round of MCTS involves selecting a leaf node to expand based on node scores, then generating a set of child nodes and scoring them for the next round. In the example below, 2 child nodes are generated per round, and a reward model is used to score them from 0 to 1. At the end, after a set number of rounds, the highest scoring answer node is returned.
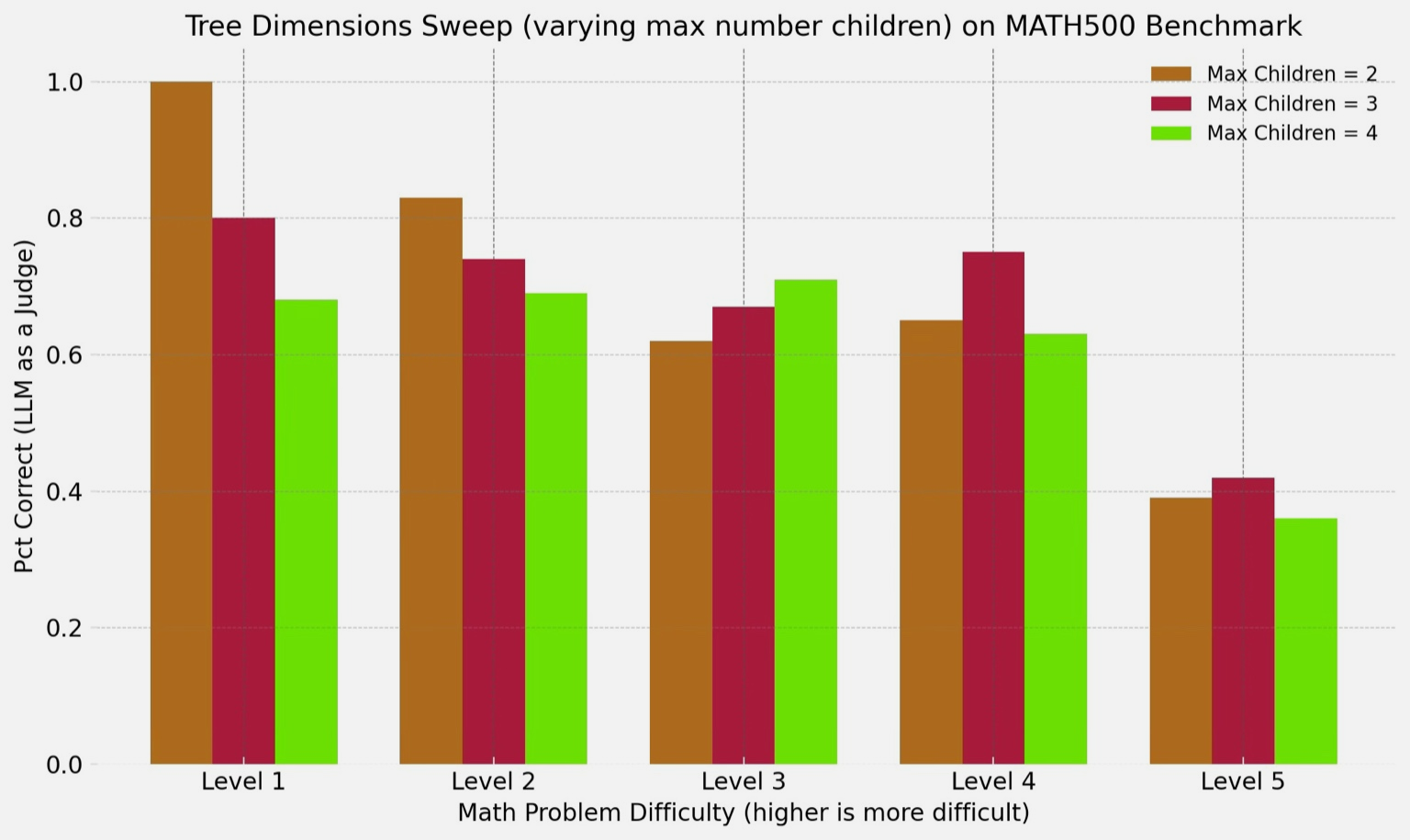
The backend solver calls LLMs over an API, and we did not train any models ourselves. Instead, we optimized things like the prompt and response processing, along with parameters that affect tree shape like max depth and number of children. We optimize for accuracy first, because this system is being used for answer validation, with latency and cost being secondary.
We also experimented with changing the max number of children per node, choosing from 2, 3, or 4. We found that overall performance with 2 or 3 max children was comparable, with 4 children doing slightly worse. We also found that fewer children tended to perform better on level 1 and 2 problems, while 3 children tended to perform better on level 4 and 5 problems.
We chose to keep 3 max children for the final app to optimize for those harder problems.
One of the challenges we faced was being able to prompt the model to output exactly what we want. Before, we provided a complex prompt with examples of what we expect, and then parsed the output. However, we found that the model would want to solve the problem in one step, or instantly give out what the correct answer is, along with other issues. We then used a structured output client that included separate fields for the solution state text at the current node, a title for that step, and a boolean for whether the node represented a final answer to the reasoning tree. We found that the structured output prompted the model clearly on the expectations of the output, and allowed the model to consistently output what we expect.
Another major challenge was dealing with latency. Due to the use of MCTS, each step generation required multiple calls to LLMs with different policy prompting. We were able to initially reduce our latency from 16 seconds to 8 seconds by implementing concurrency.
Evaluation
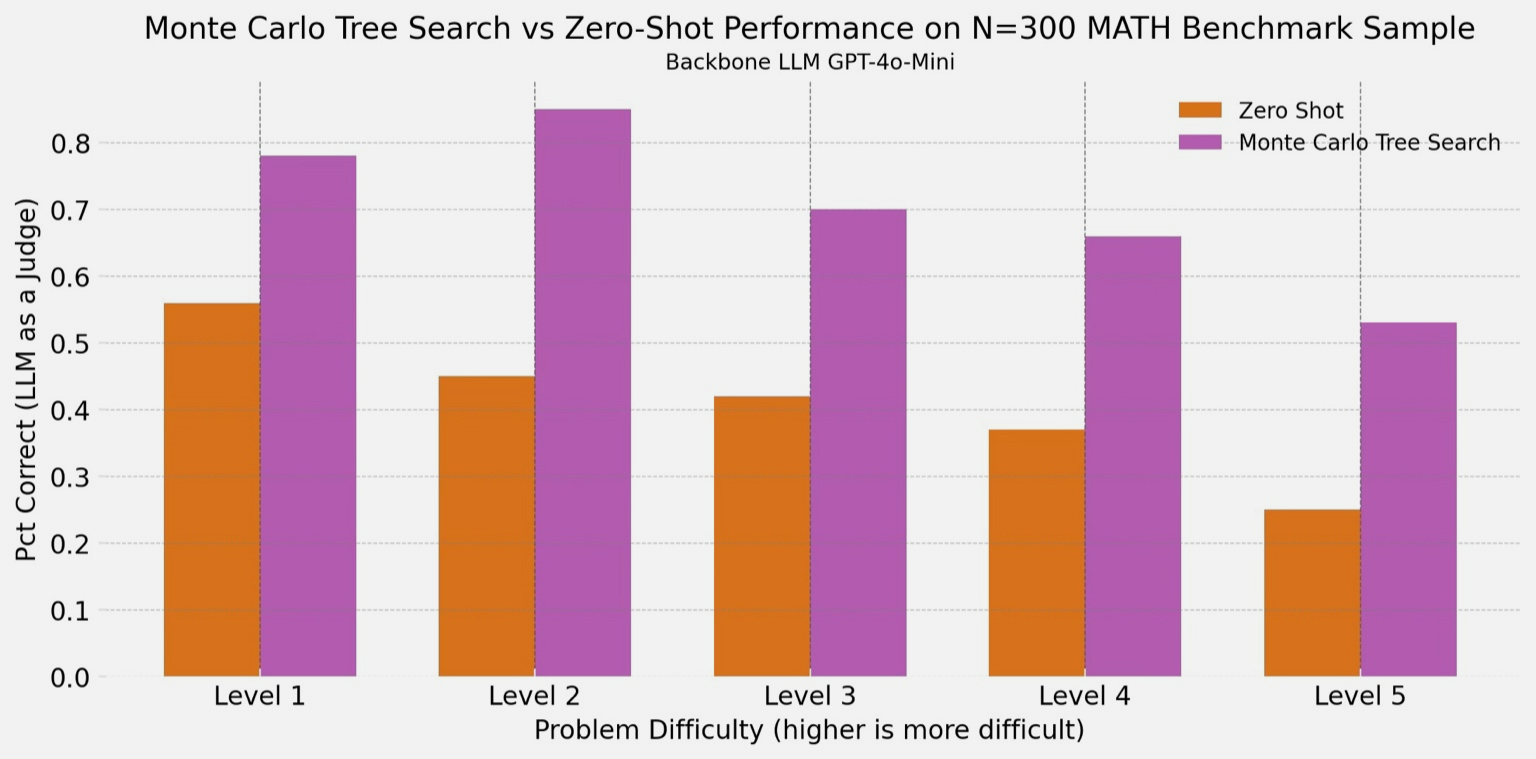
We tested our MCTS solver against zero shot performance, where we just ask the LLM to solve the problem and use its response as the answer. Using gpt-4o-mini with our custom scaffold, we found that the MCTS solver increased the proportion of problems we get correct by around 30 percentage points across all levels. So this backend solver system tends to validate answers more accurately than we could if we used gpt-4o-mini alone.
Key Learnings & Impact
We have found that using Monte-Carlo Tree Search as a method for solving problems using LLMs applies well to tutor students on solving math problems. Our product allows students to work on hard math problems being gently guided by AI rather than explicitly shown a solution, similar to the way a peer or teacher might help someone think through a problem. Even AI solutions that provide step-by-step breakdowns of hard problems don’t solicit intermediate human feedback, and are thus less interactive. With StepWise, intelligent interaction with the model is required to get to a correct solution.
In addition, this approach can be used at the forefront of an LLM’s reasoning capabilities (for example, on very hard graduate level mathematics topics). Here, the model would be entirely dependent on good human feedback, and the generated reasoning tree could be used in a labelled dataset for improving LLM math performance in the future. High-quality labelled datasets of these kinds of reasoning trees are often bottlenecks in frontier AI development.
The global edTech market size was estimated at $220 billion in 2023, and is expected to grow significantly over the next few years. Additionally, user provided feedback of mathematical reasoning steps could be used as labels to improve reasoning LMs. This presents an opportunity to also tap into the AI data labelling market.
Future Improvements
Future improvements to the product could include allowing users to upload images of math problems for convenience instead of having to type out every problem. More improvements could be made to soliciting even more feedback from the users at certain steps to further increase interactivity. For example, if a user was trying to solve a complex polynomial problem in the current equation, expanding certain nodes to factor the polynomial or perform division would have the LLM show the math involved to complete that step. If we instead had the user do the math for these steps manually and then provide that as feedback, that could further increase the interactivity of the system.
Acknowledgements
We want to thank our instructors, Cornelia Paulik and Ramesh Sarukkai, and our classmates in Section 5 of the capstone class for their support and suggestions.
References
MATH dataset: https://github.com/hendrycks/math
MATH-500 dataset: https://huggingface.co/datasets/HuggingFaceH4/MATH-500
MCTS implementation based on https://github.com/kohjingyu/search-agents