

 Saxenian")






Safewalk for the Visually Impaired
Introduction
The streets we live on are often filled with various obstacles, and unexpected hazards can arise at any moment, making it challenging for visually impaired people to walk safely. SafeWalk is a tool designed specifically to aid visually impaired individuals navigate these streets securely. SafeWalk identifies obstacles near the user and provides timely audio alerts using the fine-tuned object detection model on-device. Additionally, through the integrated visual language model, users can receive detailed descriptions or ask questions about images captured in real-time through their phone's camera.
Problem & Motivation
- Problem statement: Over 36 million people globally live with severe visual impairments — a number projected to double within the next 30 years. Meanwhile, more than 270,000 pedestrians die annually on roads. Navigating outdoor environments poses a daily challenge for many visually impaired individuals, with limited access to reliable tools to assist in real-time hazard detection and spatial awareness.
- Target users: SafeWalk is designed for visually impaired individuals living in urban areas who have access to a smartphone. Our product supports voice interaction, multiple languages, and on-demand scene description to accommodate various levels of vision impairment and preferences for interaction.
- Market impact: The assistive technology market was valued at $3.9 billion in 2021 and is expected to grow to $13.2 billion by 2030. We aim to support and empower this growing demographic by making mobility tools smarter, more personalized, and accessible to all.
- Domain expert insight: In our user research, we interviewed a domain expert to better understand the daily challenges visually impaired individuals face. The conversation emphasized the need for proactive, adaptive, and context-aware assistance — affirming the direction of SafeWalk's real-time object detection and voice-guided features. Their feedback played a key role in shaping our alert rules and scene description functions.
- Our mission: SafeWalk is dedicated to building a world equally accessible to all. Our mobile app combines cutting-edge object detection and visual-language models to empower visually impaired individuals with the safety, independence, and confidence to navigate their surroundings.
Data Source & Data Science Approach
Dataset Overview
- Volume: ~15GB total, over 90,000 labeled images
- Sources: COCO dataset, Public Images from Robowflow, Kaggle
- Labeling Tools: Roboflow Annotation Tool + Manual QA
Object Classes
- Common Classes (14): Person, Bicycle, Car, Motorcycle, Bus, Truck, Traffic Light, Fire Hydrant, Stop Sign, Parking Meter, Bench, Bird, Cat, Dog
- Additional Classes (13): Pothole, Scooter, Tree, Trash Bin, Bollard, Fence/Barrier, Traffic Cone, Bad Roads, Crosswalk, Pole, Stairs, Upstairs, Downstairs
Challenges & Solutions
Challenges
- Mislabeling and noise in public datasets
- Minority classes like potholes hard to source
- Discrepancies between real-world and training data
Solutions
- Manual relabeling and quality control
- Data augmentation and undersampling strategies
- Custom datasets captured with GoPro / phone cameras
Preprocessing Workflow
- Data augmentation for minority classes (rotation, flipping, brightness)
- Undersampling of dominant classes (e.g., person)
- Manual quality checks and relabeling
- Dataset split: 80% train / 10% validation / 10% test
Project Objective 1:
YOLOv5s - Obstacle Detection Model
We selected YOLOv5s as our base model for object detection due to its lightweight structure and fast inference speed.
Model Comparison
| Model | Precision | Recall | mAP 0.5 | mAP 0.5-0.9 |
|---|---|---|---|---|
| Yolo v5s | 0.65 | 0.48 | 0.52 | 0.31 |
| Yolo v7s | 0.63 | 0.33 | 0.37 | 0.20 |
| Yolo v11s | 0.66 | 0.53 | 0.56 | 0.37 |
- Deployment: Optimized using TorchScript for Android compatibility
- mAP 0.5: Mean Average Precision calculated using a single Intersection over Union (IoU) threshold of 0.5.
- mAP 0.5–0.9: Mean Average Precision averaged over multiple IoU thresholds, ranging from 0.5 to 0.95 in increments of 0.05.
Fine-Tuning Strategy
- Changed optimizer from SGD to Adam
- Lowered learning rate from 0.01 to 0.001 for better convergence
- Increased training epochs to 100
- Implemented Class Weight Parameter
- Addressed class imbalance with undersampling and augmented oversampling
- Applied relative threshold by class by best F1 score
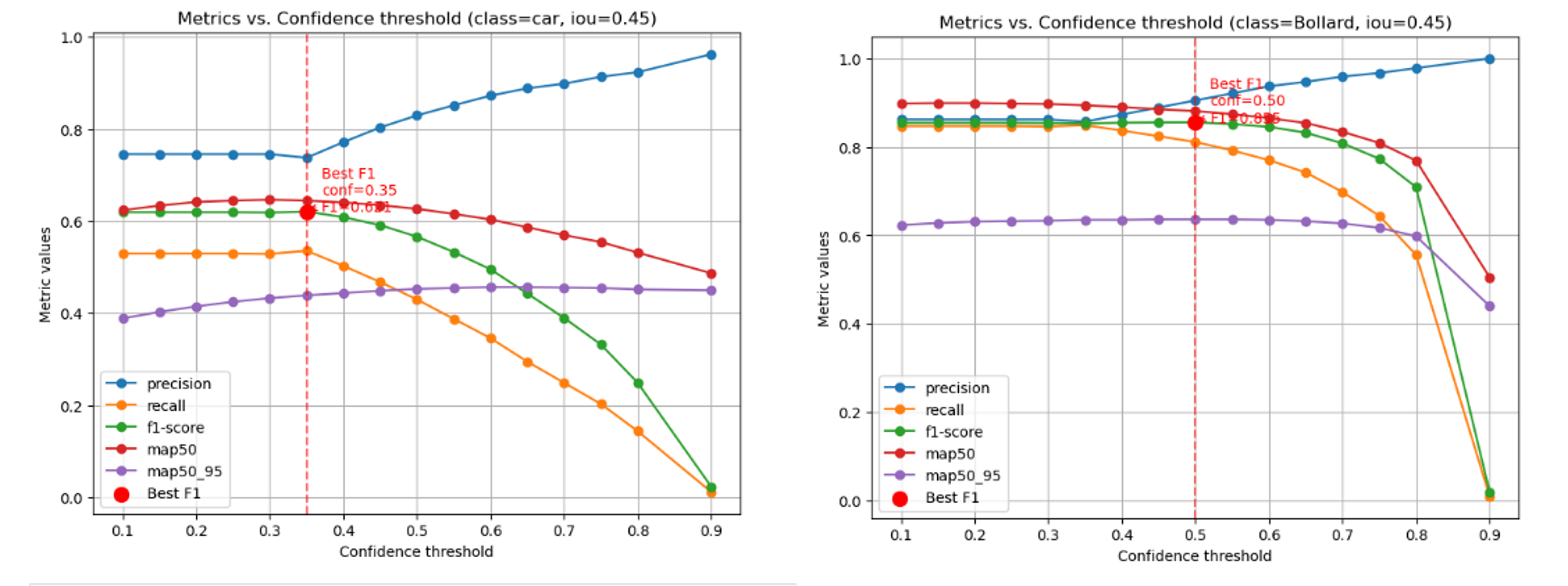
Examples of relative threshold
Final Result
After fine-tuning, the model showed improvements across all key performance metrics:
| Model | Precision | Recall | F1 Score | mAP 0.5 | mAP 0.5–0.95 |
|---|---|---|---|---|---|
| Basemodel | 0.65 | 0.48 | 0.54 | 0.52 | 0.31 |
| Fine-Tuned model | 0.82 | 0.67 | 0.73 | 0.76 | 0.54 |
Precision-Recall curve moved to the top-right corner showing the improvement after fine-tuning
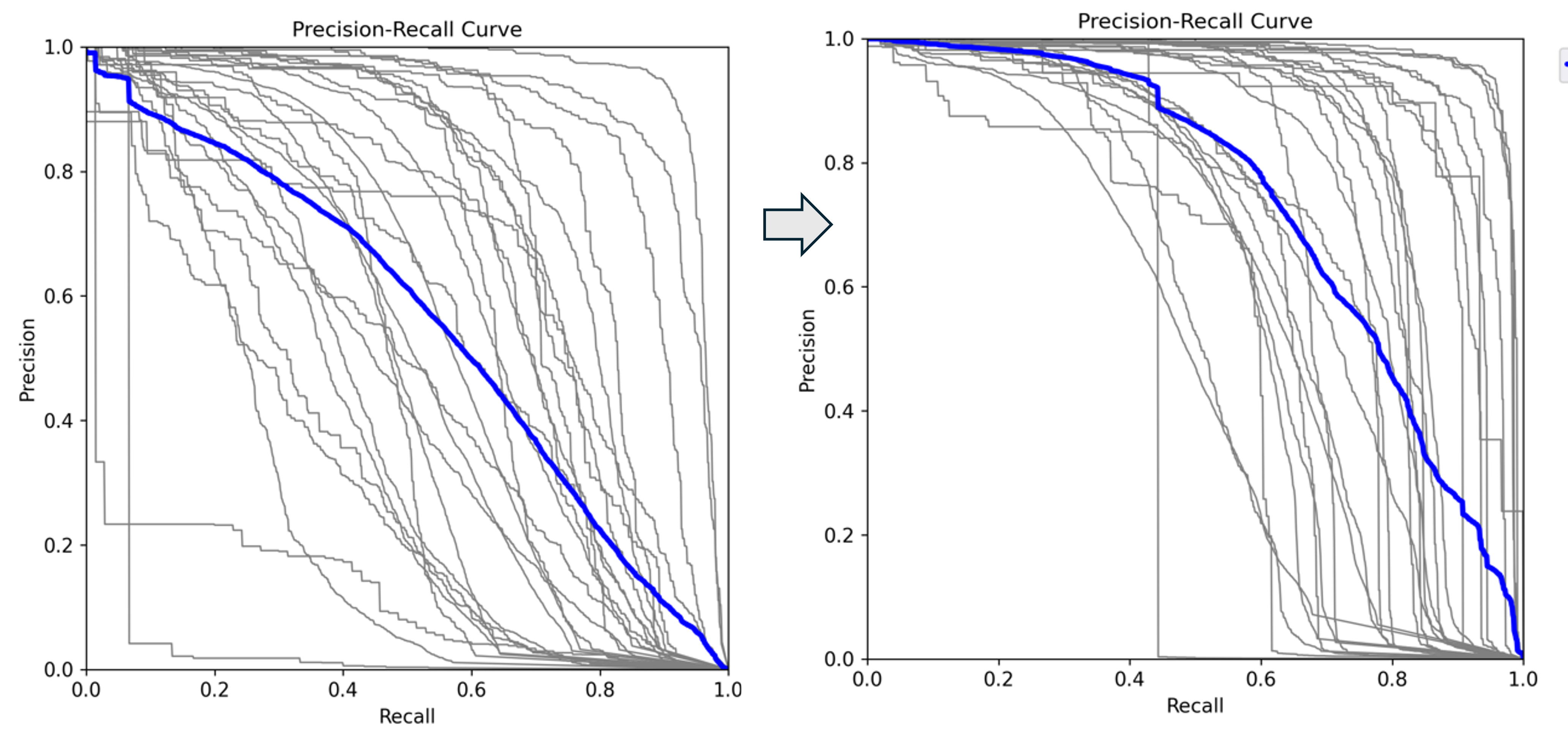

New Class Detected After fine-tuning
Project Objective 2:
Alert Rule System
Key Objective
Our adaptive alert engine uses YOLO outputs to trigger spoken warnings based on real-time detection and object location. This system aims to enhance safety while minimizing alert fatigue.
- To reduce fatigue of users by alerting only when it matters
- To enhance usability with directional guidance
- To provide safer decision-making by right-time warnings based on front-end rule sets
Alert Rule Development
Essentially, SafeWalk does not alert for every object detected by the model. It only provides alerts when users need to make safer decisions. To achieve this, the system checks various parameters of each object's bounding box—such as its center width, height, top, and bottom. As an object gets closer to the user, its bounding box becomes larger, indicating an increase in both height and width. Additionally, by analyzing the center position of the bounding box, the system can determine whether the user is approaching the object from the right, left, or directly in front.

Bounding box logic for directional alerts
Adaptive Alert
There are two modes. The detection mode is the initial alert that users receive. In this mode, objects are detected along with directional guidance (right, left, or in front), ensuring users are aware of them ahead of time. When an object moves closer to the user, a stronger alert is triggered, stating, “Be careful {obstacle}.” Different parameter conditions are used to differentiate these two modes.

Two-stage adaptive alert system
Challenges & Solution
Developing consistent alerting rules for all object classes due to drastically different shapes and sizes—such as wide cars, narrow and short bollards, and moving people—required extensive testing and adjustments. We employed a custom test mode to evaluate how bounding boxes behaved in real-world conditions and tuned our logic accordingly.

Custom test mode for bounding box calibration
Project Objective 3:
Qwen2 - Scene Description Model
To provide clear and context-rich visual descriptions, we evaluated several Vision Language Models (VLMs). Qwen2 consistently outperformed Paligemma in both qualitative and quantitative metrics.
Overall Evaluation Summary
We scored models on three custom designed metrics across 30 real-world urban scenes:
- Navigation Safety: Identifying obstacles, hazards, and safe paths
- Spatial Orientation: Helping users build a mental map
- Environmental Awareness: Providing relevant context (e.g., weather, time, ambiance)
Overall Evaluation Scores
| Model | Navigation Safety | Spatial Orientation | Environmental Awareness | Overall |
|---|---|---|---|---|
| Paligemma | 3.0 | 2.1 | 2.2 | 2.4 |
| Qwen2 | 3.9 | 3.8 | 3.9 | 3.9 |
| Gap | +0.9 | +1.7 | +1.7 | +1.4 |
Why Qwen2?
- 67% better performance across all evaluation metrics
- 4–6x more detailed descriptions (avg. 65–70 words vs. 11–12)
- Higher accuracy in describing surroundings, layout, and spatial cues
Scene Example: Which Model Describes Better?
We prompted both models with the same question for the picture shown:

Paligemma’s Response
“The image is a video of a crosswalk with a person and a car in the middle of the road.”
Qwen2’s Response
“The image shows a city street scene during the day time. There are several people crossing the street at the pedestrian crossing marked with yellow line. The street is relatively wide and has a few cars parked along the side. There are trees with blooming flowers likely cherry blossoms…”
Scoring Comparison
| Metric | Paligemma | Explanation | Qwen2 | Explanation |
|---|---|---|---|---|
| Navigation Safety | 2.5 | - Mentions person & car - No crosswalk or signals - Vague on safety context | 3.0 | - Notes pedestrian crossing - Mentions people walking - No traffic signal info |
| Spatial Orientation | 1.0 | - Only says “crosswalk” - No layout or direction - No reference points | 4.0 | - Describes street & parked cars - Mentions crosswalk & layout - Good scene structure |
| Environmental Awareness | 1.0 | - No weather/time info - No surroundings - Just car & person | 3.8 | - Mentions trees & cherry blossoms - Notes daytime setting - Adds calm ambiance |
| Overall | 1.5 | - Object-level only - Missing context - Not helpful for navigation | 3.6 | - Balanced description - Good spatial & environmental cues - Supports user needs |
Metrics-Based Caption Evaluation
We also evaluated the generated descriptions using NLP similarity metrics between model captions and human-written ones, Qwen2 also has higher scores across:
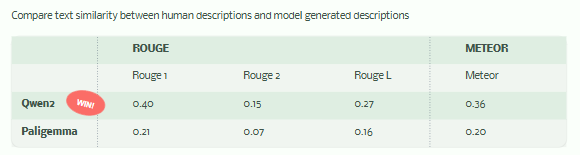
Qwen2 outperforms in ROUGE and METEOR, showing more overlap and fluency with human references
How to use the Safewalk App

System Architecture
SafeWalk integrates mobile, vision, and language AI technologies into a seamless system that assists visually impaired individuals in real-time. Below is a breakdown of our core components.
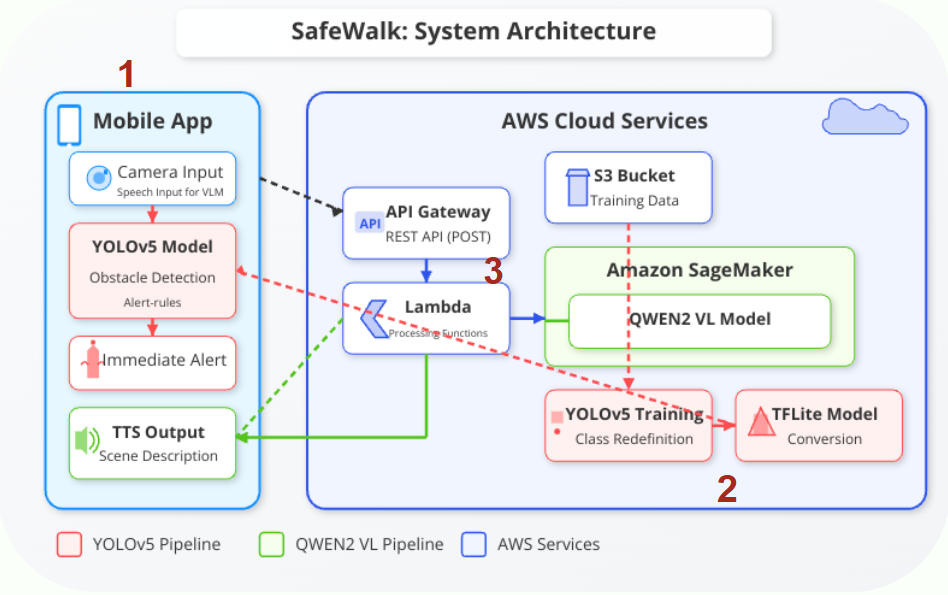
Architecture overview: Front-end app orchestrates detection and description flows
1. Mobile Front-End
- Developed in Flutter for cross-platform capability
- Real-time video feed with overlayed obstacle detection results
- Voice-based interaction and feedback with gesture control
- Front/back camera toggle + fast alert trigger system
2. YOLOv5s Obstacle Detection
- Trained on 90,855 labeled images across 27 object classes
- Converted to TorchScript for on-device performance
- Detects and classifies objects with bounding boxes
- Provides spatial inputs for the voice alert logic
3. Qwen2 Visual Language Model (VLM)
- Cloud-hosted using AWS SageMaker + Lambda
- Receives cropped image input and returns natural language captions
- Optimized prompt engineering for environmental awareness
- Audio output is synthesized using TTS for user-friendly feedback
Deployment Strategy
- YOLOv5s: Runs on-device via TorchScript for low-latency and offline use
- Qwen2: Accessed via secure REST API for scalable and language-rich output
- Designed for modular expansion: wearable camera support, iOS app, etc.
Key Learnings & Impact
- A customized Yolo model: New outdoor classes, large datasets, decent performance, reasonable training costs.
- Informative alerts: Additional colors on the position of objects based on the boundary of boxes; VLM integration for detailed descriptions.
- Efficient deployment: Yolo model running on device for low latency; VLM model via API for light App size
Future Works
- Expanding Operation System Compatibility: Currently our App is available on Android. We could expand to cover IOS version and enable functionalities available in Apple devices.
- Optimizing Alert Rules with AI: Currently our alert rules are manually refined based on test users’ experiences. Hopefully, alert rules can be optimized with AI models to adapt to the size of objects in camera.
- Expanding Global Services: We now have one customized Yolo model based on training images sourced disproportionally from Asian countries. Customizing object detection models for specific countries or cities based on users’ locations can improve the performance. While we already integrated multiple languages, such as Spanish, German, French and Russian, we still want to enhance the translation quality and provide more multilingual services.
- Wearable Device Integration: Ideally, our App can connect with wearable sports cameras for hands-free options Other cost-efficient solutions should also be under consideration.
Acknowledgements
We would like to sincerely thank Joyce Shen and Zona Kostic for their continued support and encouragement throughout this project.
Course
Data Science 210. Capstone , Spring 2025More Information
