

 Saxenian")






Homiere: Personalized Home Search
Home Sweet Homiere
Problem & Motivation
Despite technological innovations transforming many industries, real estate has been slow to embrace advancements, with the home search process remaining one of its most under-optimized areas. The core functions of finding a home continue to rely heavily on human effort, as buyers manually sift through countless listings with basic filters. Moreover, the 2024 National Association of Realtors (NAR) settlement introduced regulatory changes, empowering buyers to negotiate their agent's fees, ultimately enhancing their autonomy. These shifts are already having a tangible impact on the industry, with buyer's agent fees dropping from an average of 2.62% in early 2024 to 2.55% by August 20241. This signals a trend towards greater buyer control and a need for more efficient tools in the home search process.
Solution
There's no place like Homiere
The combination of a technological gap and regulatory shifts creates a unique opportunity for Homiere, an AI-powered proptech solution that offers a personalized home search experience. Homiere is designed to provide a more transparent, customized, and efficient process for buyers, allowing them to input their specific preferences and receive an optimized list of homes that match their criteria. This is achieved by preprocessing property listing data—textual, tabular, and image-based—while integrating external data such as crime rates, inflation, air quality, location details, and more. By leveraging NLP, LLMs, multimodal models, and other advanced data science techniques, Homiere delivers a comprehensive, data-driven home search experience.
Data Source
Homiere's core data is scraped listing data. For our MVP, we are starting with over 10,000 listings in California. Supplemntal to this data are:
- Air quality index
- Crime rate
- Inflation rate
- Schools and their ratings
- Nearby locations
- Walk, transit and bike scores
- Property photos

Data Pipeline & Technical Architecture
Homiere’s data source is stored in parquet format on Amazon S3, enabling faster loading and lower latency. We leverage Streamlit for our user interface and our backend framework for fetching data from S3 and Bedrock via API calls. The fetched data is cached in-memory, parsed and used for displaying the maps and the listings results.Homiere is hosted through Streamlit on Community Cloud. Amazon Route 53 is used to redirect Homiere.com visitors to the Streamlit application. This simple architectural approach ensures that user sessions do not need to be coordinated on the backend, since the listings results information for each user lives on the client side within Streamlit. Latency is thereby dramatically lowered due to the reduced cloud communication.
Data Science Approach
When you search for a home, AI works behind the scenes to find the best matches. First, your query is converted into a numerical format using OpenAI’s text-embedding-3-large, allowing it to understand what you’re really looking for. It then searches through tens of thousands of home listings in Pinecone’s vector database, using cosine similarity and metadata filters like price and location to narrow down the results. But instead of just returning a list, a powerful AI model, Meta’s Llama 3.3 70B, reranks the homes to ensure the most relevant ones appear first. The result? A curated selection of homes that truly match to your needs.

Natural language queries are embedded and matched against listings in a vector database. LLM's are then used to summarize and re-rank results, and to support follow-up questions and clarifications.
Evaluation
Embedding Model
We used a novel approach, LLM as a judge, to evaluate our application. Because we do not have a labeled dataset for ranking quality, we employed LLM judge models (Llama 3.3 70B and Claude Sonnet 3.7) to assess the embedding and foundation models for Homiere.
Model | Leaderboard Score | Speed (emb/s) | Summary |
text-embedding-3-large | 65.46 | 1550 | State-of-the-art embedding model from OpenAI |
all-mpnet-base-v2 | 63.30 | 2800 | Good for comprehensive property descriptions |
all-distilroberta-v1 | 59.84 | 4000 | Trained on longer paragraphs, good for more detailed queries |
all-MiniLM-L6-v2 | 59.76 | 7500 | Good for mobile applications / low-compute environments |
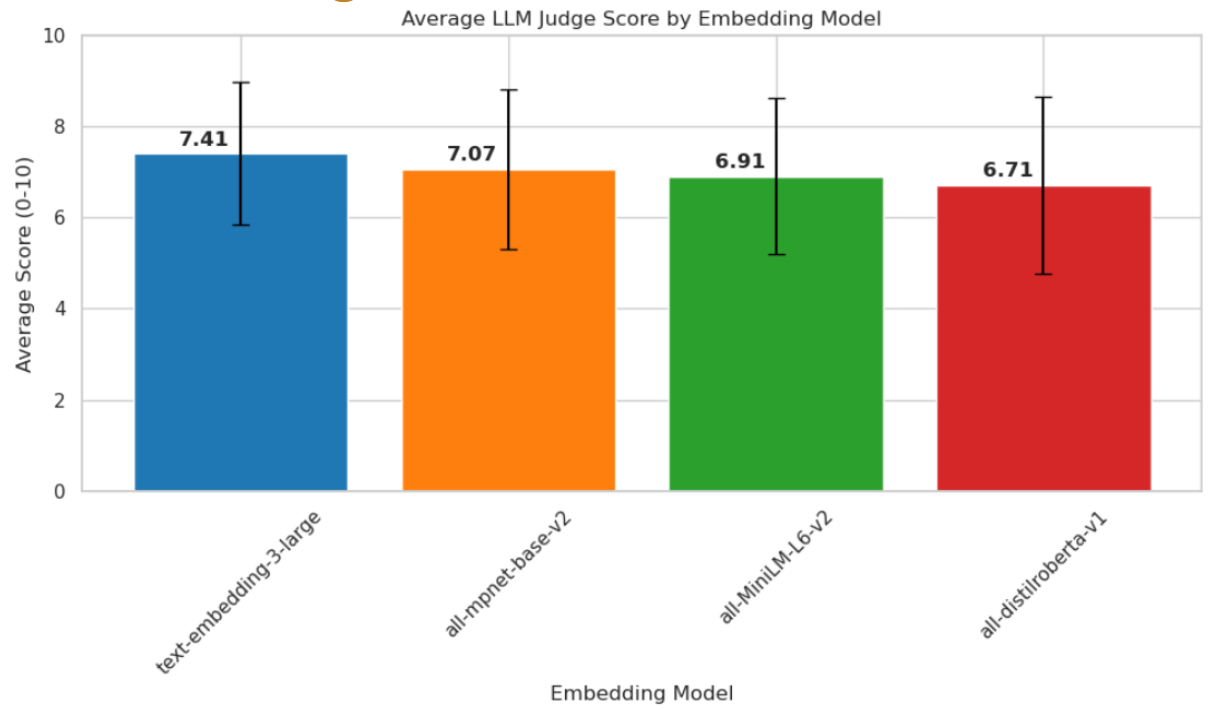
Our evaluation of embedding models using the Llama 3.3 70B LLM judge showed text-embedding-3-large outperformed the alternatives with the highest average score (7.41), and is the evaluation model chosen for our final Homiere solution.
Foundation Model
Model | Context Window | Summary |
|---|---|---|
Llama-3.3-70B | 128K tokens | High-performance open model, significant hardware requirements |
GPT-4o-mini | 128K tokens | OpenAI's fast, affordable small model for focused tasks |
GPT-4-Turbo | 128K tokens | High-performance model with strong reasoning capabilities |
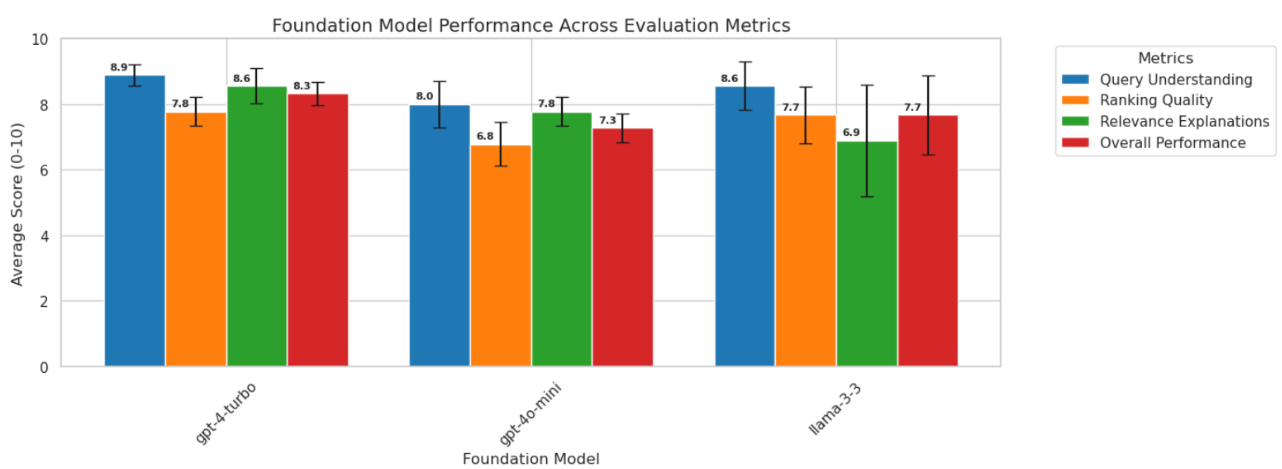
Out of all three models assessed in depth, GPT-4-Turbo emerged as the top performer according to Claude Sonnet 3.7 as our LLM judge, boasting the highest overall performance score (8.3) — a notable improvement over the next best score achieved by Llama 3.3 (7.7). However, this comes at the cost of significantly longer execution time (46.1s compared to 28.9 for Llama 3.3 and 26.1s for GPT-4o-mini). Llama 3.3 offered the best balance of speed and performance, and is the foundation model chosen for our final Homiere solution.
Key Learnings & Challenges
An important learning from this project is that selecting the right embedding and large language model significantly impacts retrieval and summarization quality. We also learned that prompt engineering requires extensive iteration and refinement to achieve optimal results - a process that consumed significant development time but ultimately proved crucial for system performance. Additionally, our evaluation process taught us that LLM-based assessment can effectively substitute for human evaluation when prompted correctly and using the right model.
The initial AWS architecture design presented challenges with API Gateway and Lambda timeout limitations. We also encountered complications with backend user session management that required infrastructure adjustments. Additionally, midway through development, we discovered issues in our feature engineering that necessitated recalculation and re-indexing of our vector database, consuming extra time and resources.
Future Work
- Data: Attain API access to live listings
- Model: Adopt data augmentation techniques in InPars to overcome data limitations, better understand nuanced user queries, and improve its oerall recommendation capabilities.
- Feature Enhancement: Incorporate user feedback feature enhancements.
Acknowledgements
References
Redfin. (2024). The typical buyer’s agent earns 2.55% in commission, a rate that has declined since the NAR settlement was announced in March. Retrieved 18 January 2025.
Sivasothy, S., Barnett, S., Kurniawan, S., Rasool, Z., & Vasa, R. (2024). RAGProbe: An automated approach for evaluating RAG applications. arXiv.
Yang, S., Zhao, Y., & Gao, H. (2024). Using large language models in real estate transactions: A few-shot learning approach. arXiv.
Haurum, K. R., Ma, R., & Long, W. (2024). Real Estate with AI: An agent based on LangChain. Procedia Computer Science. Elsevier.
McKinsey & Company. (2023). Generative AI can change real estate, but the industry must change to reap the benefits. Retrieved 30 January 2025.
Veluru, C. S. (2023). Revolutionizing real estate: AI-driven insights from historical data for smart property decisions. Journal of Artificial Intelligence & Cloud Computing.
Adelusola, M. (2024). High-Fidelity Generative AI for Financial and Real Estate Models: Integrating Adaptive Learning and Explainable Fairness.
Asimiyu, Z. (2024). Explainable Generative AI in Financial and Real Estate Applications: Achieving High-Fidelity Results Through Adaptive Learning.
Cacciamani, C., Conso, A., Zaltron, S., & Dinicolamaria, D. (2024). Artificial intelligence in the real estate industry. In R. López-Ruiz (Ed.), Complex Systems With Artificial Intelligence (Chap. 4). IntechOpen.