

 Saxenian")





Intelligent Watchdog
Project Overview
Intelligent Watchdog is a platform for detection. It uses a combination of the internet of things (IoT) and machine learning to give a comprehensive view of what is happening at home, when you aren't at home.
- Activity: Intelligent Watchdog will send an alert about which activities family members are engaged in: reading a book or playing on a tablet.
- Search: Intelligent Watchdog allows parents to review what family members are doing at different times of the day without having to comb through hours of video.
- Security: Intelligent Watchdog will identify and send an alert when an unfamiliar face enters your home.
The Challenge
Working with image data is difficult.When we began our capstone journey, we did not realize the amount of compute power, volume of data, and variety of data required to support an image recognition system.Our scope statement for this project has been pared down over the term to two objectives:
- First: Detect and identify faces in real-time.
- Second: Detect whether a person is reading a book, or watching a tablet.
Image Capture Device
For the IoT image capturing component we utilized a Raspberry Pi connected to the cloud. The Raspberry Pi captures images every minute. Timestamped images are then passed to cloud servers which are running our machine learning models.Although inexpensive, the Raspberry Pi experienced the following challenges:
- The clarity of the photos were grainy at best.
- Depending upon the time of day, lighting conditions will change thus interfering with the ability of the Raspberry Pi to capture a clear image of a person. For example, exceptionally bright or exceptionally dark conditions resulted in a much smaller image recognition rate.
- Video capture proved too computationally expensive for the Raspberry Pi.
- We had high hopes that that we may be able to complete much of the imaging parsing at-the-edge; however, the Raspberry Pi's processor was only strong enough to capture images and upload them to an AWS S3 bucket.
How our application works
Given our abundance of research and short time frame, we determined that a hybrid approach was best to achieve our project objectives: First, we used pre-trained OpenCVHaar Cascades to parse faces and activities from incoming images captured by the Raspberry Pi:
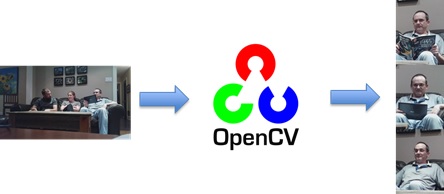
Second, we prompted our users to uniquely label each image:

Third, we fed our labelled training data into Tensorflowto train our model:
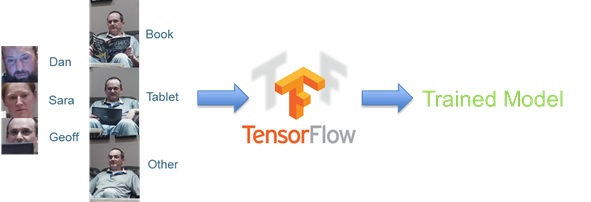
Finally, we now have a trained model that can make inferences regarding which faces and activities the Raspberry Pi captures:


Parsing Engine: OpenCV
For our parsing engine we used OpenCV to provide dimensionality reduction in the images submitted to our prediction engine. A parsing engine is required to focus the prediction engine on just the elements of the photo that mattered the most, thus we needed to remove as much of the extraneous data as possible.For example, the photo on the left provides far too much information for the prediction engine to determine the most salient data in the image, thus resulting in a model that will not generalize. In contrast, the image on the right provides a highly focus amount of data for the prediction engine to train on.
Prediction Engine: Tensorflow
The tensorflow model we use is an Inception-V3 convolutional neural network model trained on the ImageNet Large Visual Recognition Challenge data from 2012. The model is trained to recognize other classes of images generated from our Raspberry Pi.The top layer of the model receives as input a 2048-dimensional vector for each image. A softmax layer is trained on top of the representation. Assuming the softmax layer contains N labels, this corresponds to learning N + 2048*N model parameters corresponding to the learned biases and weights.Our model trains quickly with as few as 30 images per face or activity. We feel that the model does produce accurate results given good training data; however, our ability to provide good training data with a Raspberry Pi is questionable without perfect lighting conditions.
Model Accuracy and Evaluation:
Table below lists testing status for each of the categories. We found varying results for each of the conditions as the nature of test cases are very different.
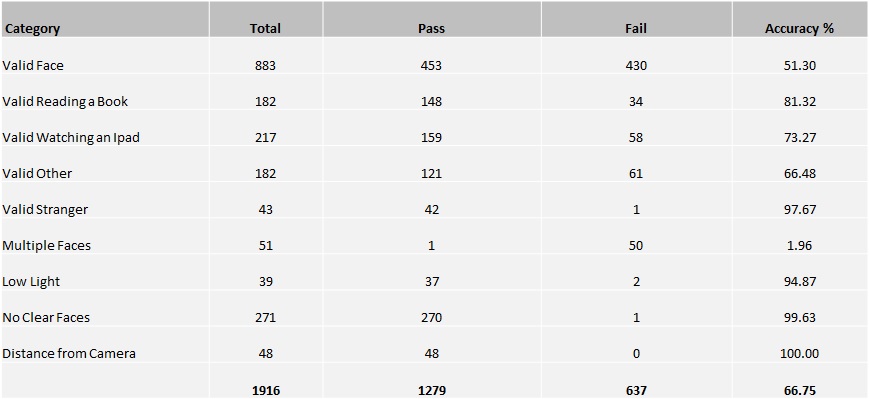
Table below lists overall test results. We had over 2700 images with overall predication accuracy of 67%.
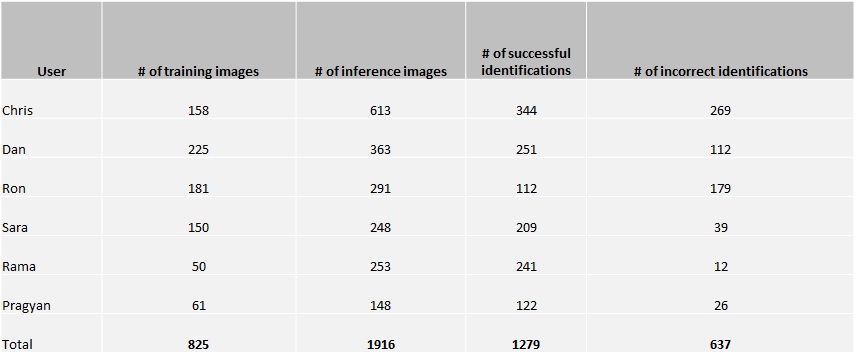
Impact and Future Possibilities
To our surprise, we discovered that there are already two entrants in our target market; one of which is a major technology company. Thus, we feel that the market has validated our product as high impact.Given that 12 weeks is an incredibly short period of time to build an image recognition system, we feel that our capstone journey has given us a strong foundation in working with image data.We feel that the future for working with image data rests with objection detection. If we are able to improve our product such that it can pick out nuanced objects in an image with complex backgrounds with a high degree of accuracy and a low amount of compute power, then the market for our product will be lucrative and diverse.To this end, we are currently optimizing our image capture device and looking to include additional context-specific training data that will help us to identify objects in an image. We are considering patent options and will pursue commercial release pending interest from investors.
Course
Data Science 210. Capstone , Summer 2017More Information


