

 Saxenian")






FakeRanks Faux Real
PROJECT OVERVIEW
Our project aims to improve classification of news sources into “credible” and “not credible” by exploiting network relationships to build upon the solid work of “Make News Credible Again”, referred to as MNCA below. Our basic premise is “bad articles cite questionable sources, good articles link to reliable sources”. We propose a simple algorithm, that is in part inspired by the Inverse PageRank of Combating Web Spam with TrustRank, and combines the score of the article in question with the scores of the cited articles in its network graph structure. Our results (see below) support the claim that there is merit in this approach.
BACKGROUND
The Problem: The “Fake News” phenomenon is very much talked about and has had far-reaching social impact, as evidenced in the 2016 U.S. Presidential election - feeding rumors, fueling divisiveness and creating an increasingly polarized society.
Three factors have contributed to the brewing of this perfect “Fake News” storm:
- First, growing demagoguery and partisan journalism have led to lowered trust in the Media, thus blurring the line between Fake and Real News.
- Second, the dramatically lowered cost of production and distribution for Fake News, which does not require expensive research or fact-checking, has led to an explosion of Fake News sites.
- Third, as more and more of the U.S. population gets its news from Social Media, these platforms have made for easy propagation of Fake News.
Given its increasing importance in the public discussion it becomes even more critical to develop tools and frameworks that can help to address this problem.
Stakeholders impacted: Being able to identify Fake News articles correctly, consistently and in an automated way, benefits several stakeholders - general public, journalists, government agencies, as well as social media channels - and reduces general distrust, partisanship and divisiveness in society.
Challenge of defining “Ground Truth”: Not surprisingly, in some ways it appears to be difficult to say which news is “fake”, as it is used as much as a factual description of objectively false information as it is as a PR tool to discredit generally factual correct articles.
We certainly want to define it as news stories whose authenticity or intent are very questionable. These can simply be articles with fictitious information, intentionally misleading propaganda, or highly biased and inflammatory commentary. In order to do this, one needs a source of “Ground Truth” - articles that are objectively and appropriately labeled as fake or not.
Existing Approaches: Currently available solutions are either manual (externally curated list of news sites that classify the news site as fake or not e.g. OpenSources), or are more focused on utilizing certain aspects of the article in question. For example, “Make News Credible Again” (MNCA) creates a classifier based on text analysis. During our project, we also became aware of an independent network-based approach by TrustServista, that appears to be in spirit similar to our project. However our solution was developed entirely independently and does not borrow any aspects from that initiative.
OUR SOLUTION
Motivation
MNCA, which was developed as a MIDS-Capstone project in Spring 2017, had achieved good classification quality, when compared to OpenSources. However, just as a person can often be evaluated in some sense by the company they keep, we believe that “an article is known by the sources it cites”. In short, our belief was that the network of cited articles provided additional information about the truthfulness of an article, and should be considered in the calculation of its estimated truth score, and credibility classification.
Approach
Our solution is focused on improving the MNCA score of an article by considering the quality and credibility of the articles it cites in its text. More specifically, we first extract the links in the text of an article and create a corresponding network graph of depth d. All nodes in the graph are initialized by the text-based scores from the MNCA application.
We then apply an algorithm inspired by Inverse PageRank (as ‘truth’ flows in the opposite direction as citations) to update the scores for the articles. More specifically we apply an iterative procedure where at each step the score of a node is updated as a combination of its previous score and the average score of its cited sources. This algorithm converges.
In the final step, we combine the original score with the score derived from the network algorithm as a simple weighted sum. We denote this combined score as “CIET” (“citation-informed estimated truth”) score.
Results
For our project, we largely relied on the classification provided by OpenSources as the “Ground Truth”. A limitation of this source however is that this classification is at a site-level rather than article level.
CIET results show an improvement over the original text-based MNCA truth score. For a simple nearest-neighbor truncation of the graph (depth d = 1), where the network score is simply an average of the MNCA scores of the cited articles, we first find that “20%” weight of the original score and “80%” to the network-derived score optimize the results. Applying this then to a broader set of articles (241 articles, 98 from sites considered ‘fake’, ‘conspiracy’, ‘junk science’, or ‘hate’ as defined in OpenSources) showed a classification improvement from 78% to 85% over MNCA.
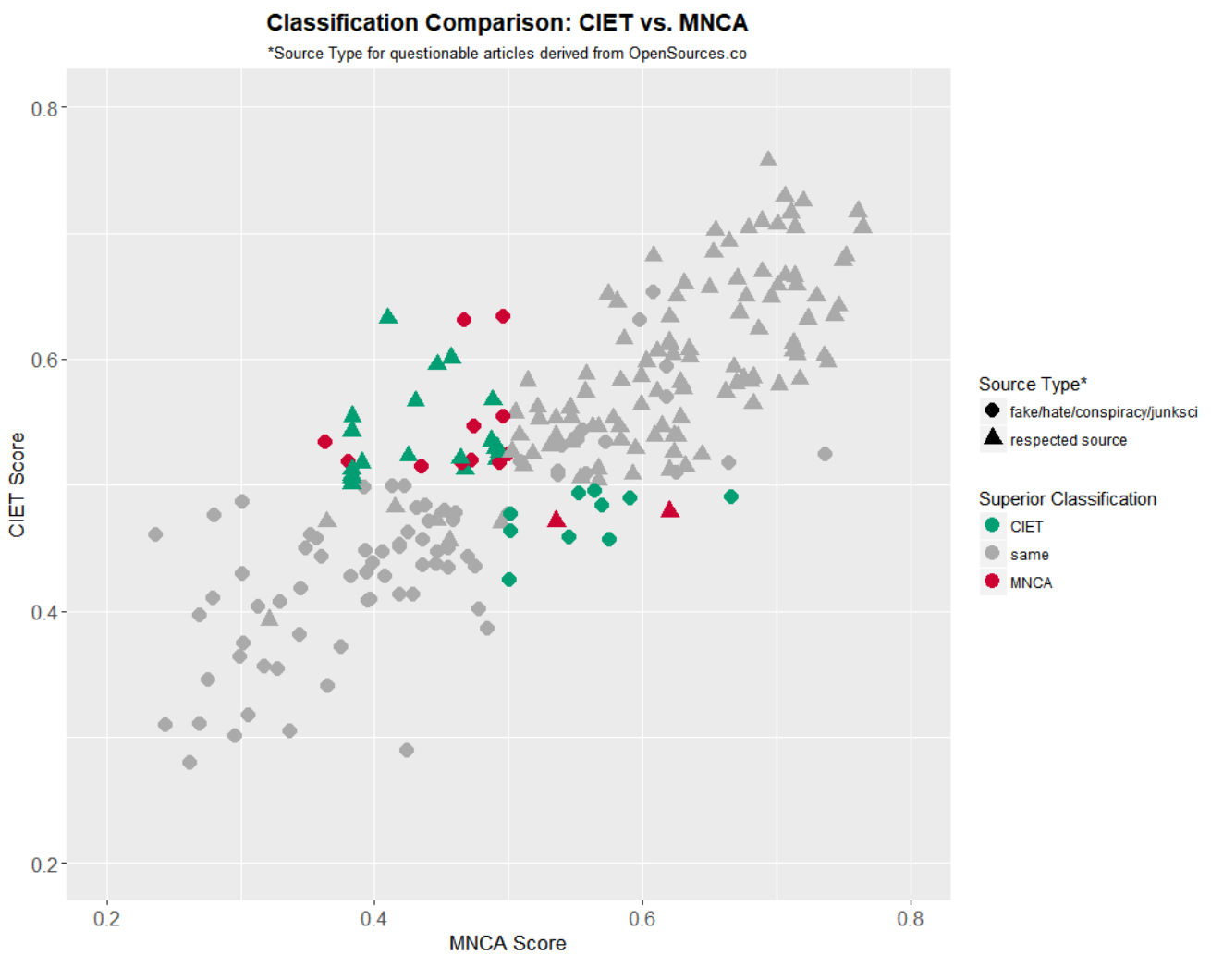
Note however that for this set of articles, there are more articles in the neighborhood of the decision boundary of 0.5 in the CIET framework compared to the same interval for the MNCA setup. More testing with a broader set of articles is required to further establish the validity of the conclusion.
Future Research
Our results show that there is promise in using network-based information in addition to features that are intrinsic to the article. In the future, we may extend this approach to assess classification improvements of depth levels larger than d=1, consider weights for nodes (that could for example be based on the PageRank algorithm), and include additional link-related features like ‘quoted claims’.
IMPLEMENTATION & TOOLS
Technical Architecture
Given our network-based analysis method, a graph database suggests itself naturally as a back-end. We chose Neo4j Community Edition for this purpose. All link extraction, modelling and testing was done in Python. The front-end visualizations are done through Flask using D3 libraries. The application is hosted on AWS. The MNCA scores are obtained through API access to their application.
Notable Libraries & Tools
- Link extraction: Newspaper, Beautiful Soup
- Flask - Neo4j Communications: py2neo
- UI Framework: Bootstrap (MIT License)
- Visualization: D3, including Mobile Patent Suit example (GNU GPL v3)
Resources Used
- Make News Credible Again: A UC Berkeley MIDS Capstone project by Brennan Borlaug, Sasanka Gandavarapu, Talieh Hajzargarbashi, and Umber Singh, Spring 2017
- OpenSources: A manually curated list of labeled websites (labels: “credible”, “fake”, “bias”, “conspiracy”, “satire” etc.)
- "How to Build a Python Web Application Using Flask and Neo4j": A very helpful tutorial for our architecture
Course
Data Science 210. Capstone , Summer 2017More Information

